堆
堆的应用场景非常多,最经典的就是堆排序。堆排序是一种原地,时间复杂度为O(nlogn)的排序算法。在实际软件开发中,快速排序性能要比堆排序好。
堆的定义
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。分别对应大顶堆和小顶堆。
实现一个堆
用数组存储一个堆。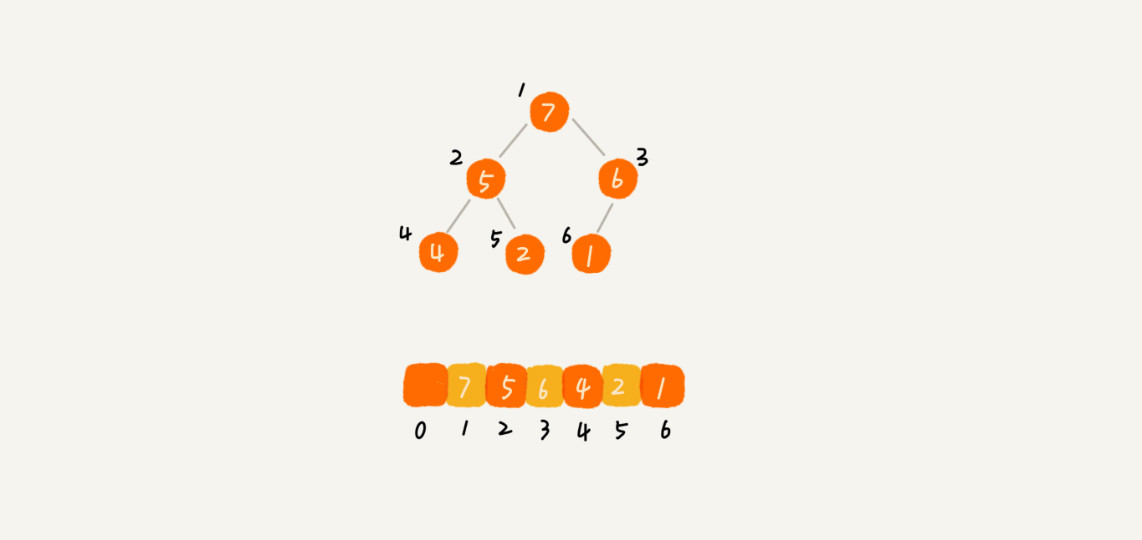
1.往堆中插入一个元素
往堆中插入一个元素后需要继续满足堆的两个特性,就需要进行调整,让其重新满足堆的特性,这个过程就叫做堆化。分为从下往上和从上往下。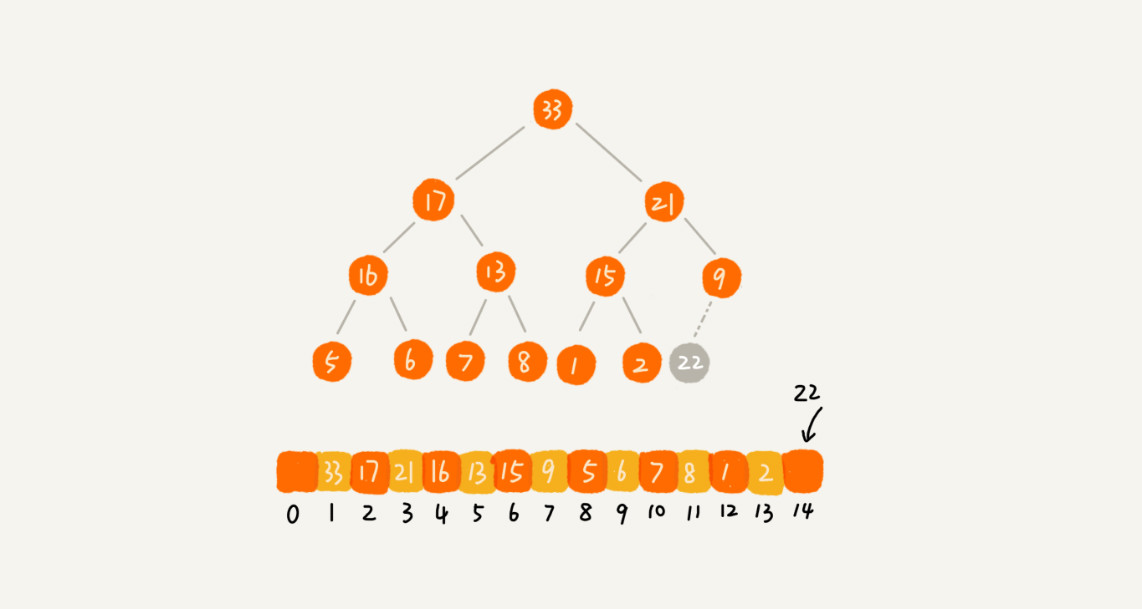
堆化就是顺着节点所在的路径从上或从下对比交换。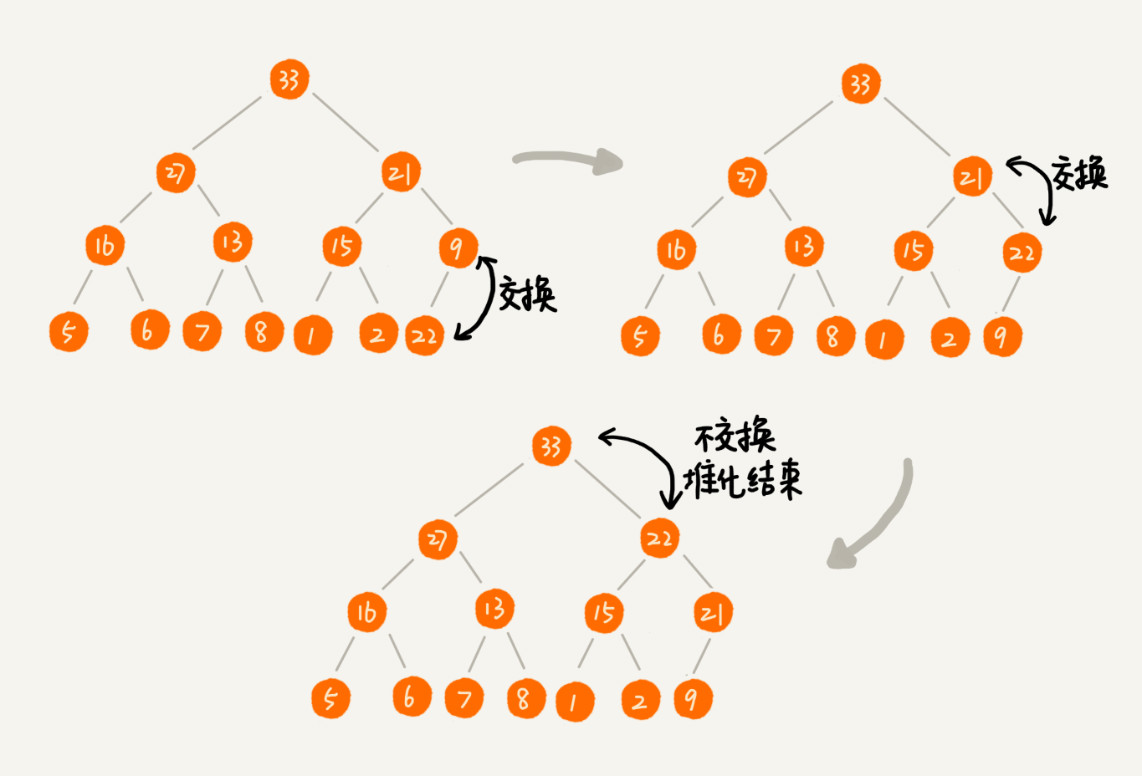
让新插入的节点与父节点对比大小,如果不满足子节点小于等于父节点的大小关系,就互换两个节点,一直重复这个过程,直到父子节点之间满足大小关系。即为从下往上。
2.删除堆顶元素
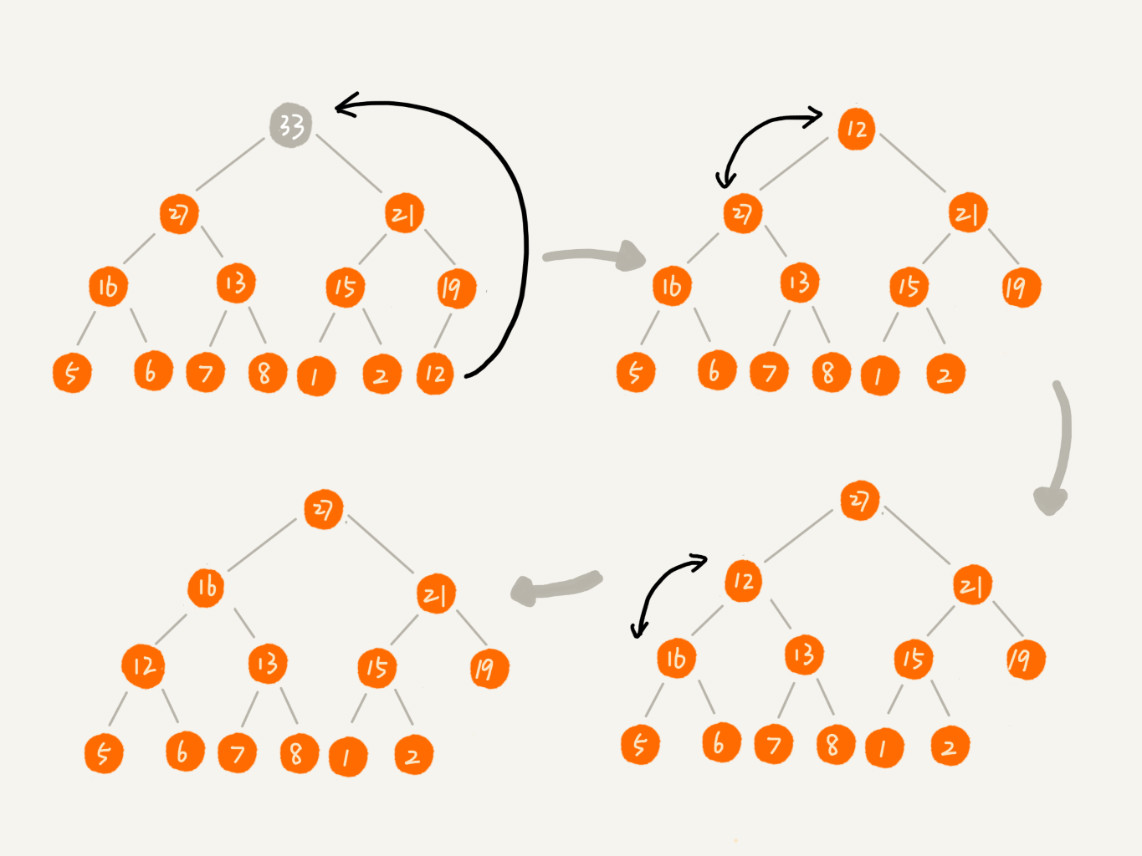
从上往下。
基于堆实现排序
时间复杂度O(nlogn),原地排序算法。堆排序分为两个大步骤,建堆和排序。
1.建堆
有两种思路,
第一种,在堆中插入一个元素,起初堆中只包含一个数据,就是下标为1的数据,然后调用插入操作,将下标从2到n的数据依次插入到堆中,这样就将包含n个数据的数据组织成了堆。
第二种思路,直接从第一个非叶子节点开始,依次堆化。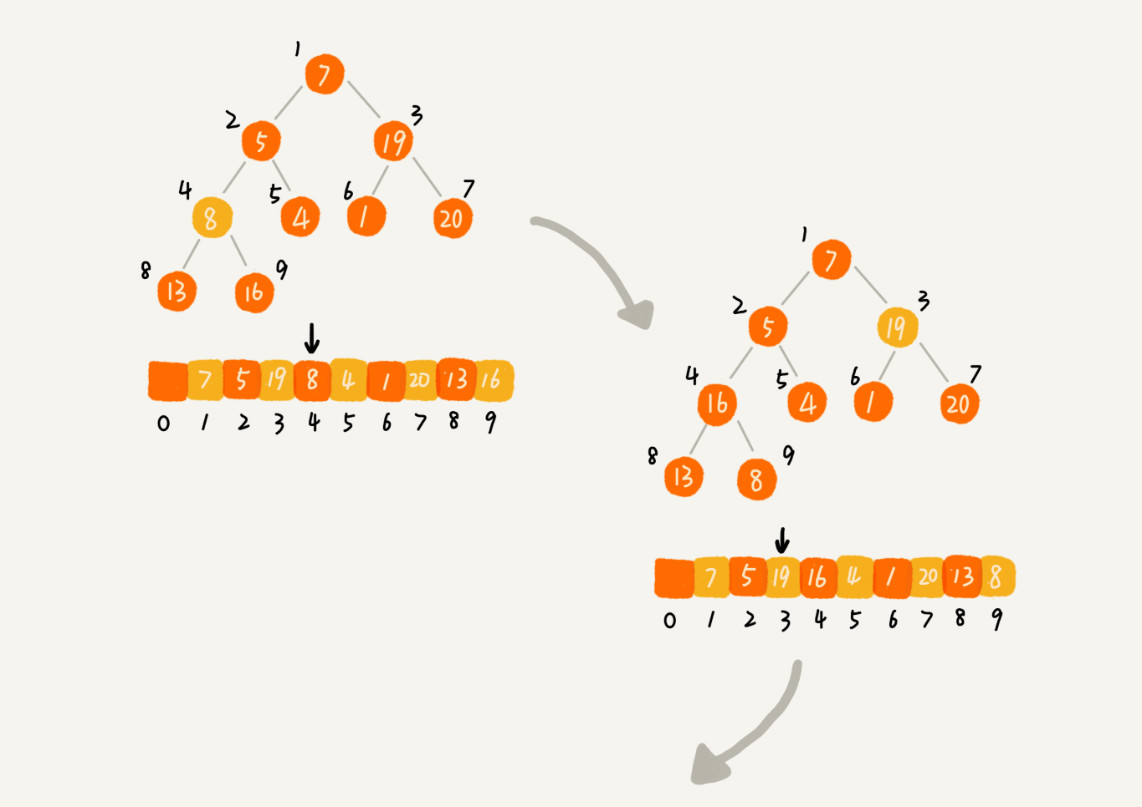
建堆的时间复杂度分析:O(n)
2.排序
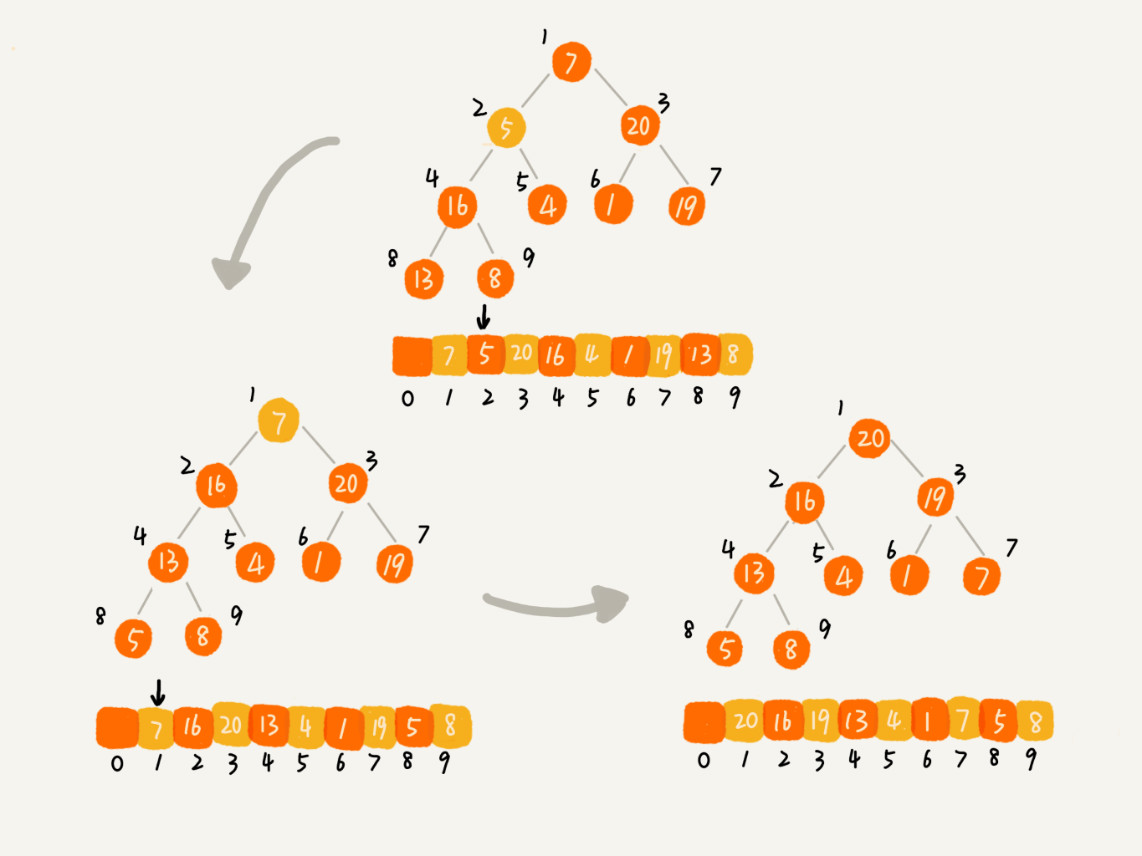
建堆结束后,数组中数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。不断取出堆顶的元素也就完成了排序。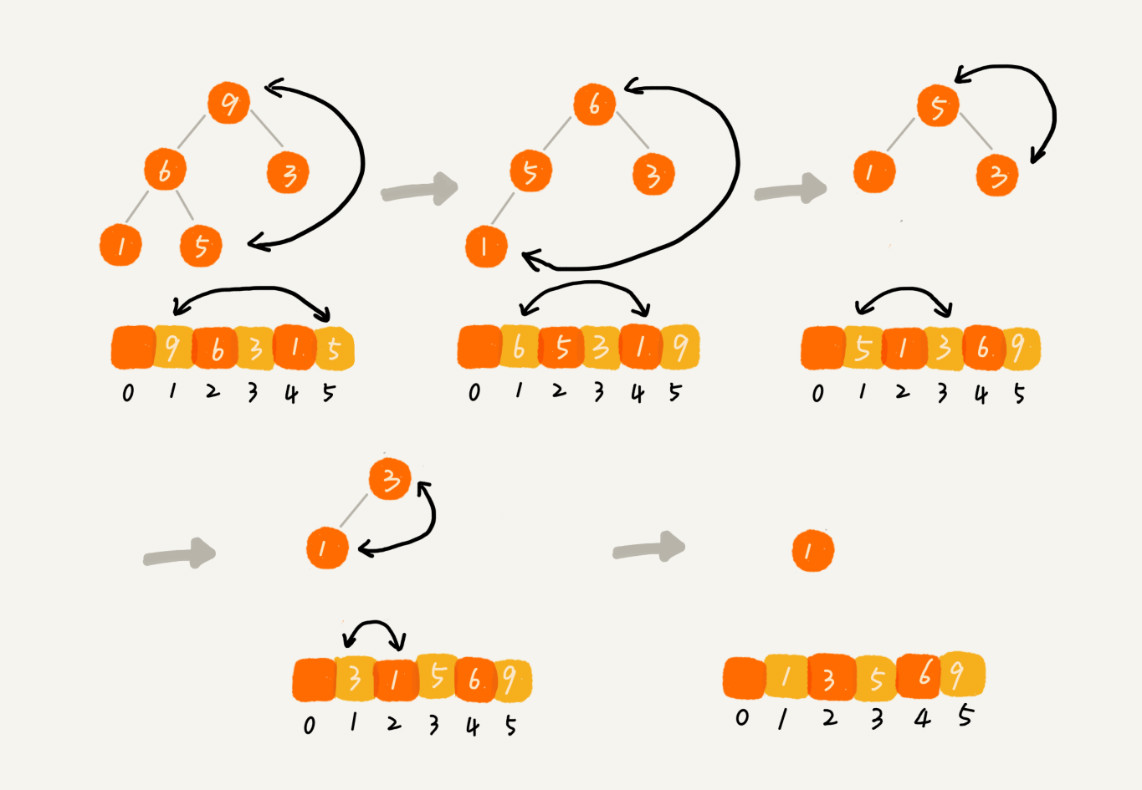
堆排序的时间复杂度、空间复杂度以及稳定性:
整个堆排序只需要极个别临时存储空间,堆排序是原地排序算法。堆排序包括建堆和排序两个操作。建堆的时间复杂度是O(n),排序过程的时间复杂度是O(nlogn),所以堆排序整体的时间复杂度是O(nlogn)。
堆排序不是稳定的排序算法,因为在排序过程中,存在将堆最后一个节点与堆顶节点互换的操作,所以就有可能改变相同数据原始相对顺序。
如果堆从0开始存储,实际上处理思路是没有变化的,唯一变化的是代码实现时计算子节点和父节点的下标公式改变了。
快排与堆排序
实际开发中,快排比堆排序性能好的两方面原因。
一,堆排序数据访问的方式没有快速排序友好。
对于快速排序来说,数据是顺序访问的,对于堆排序来说,数据是跳着访问的。这样对CPU缓存是不友好的。
二,对于同样的数据,在排序过程中,堆排序算法的数据交换次数多于快速排序。堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度降低。对于一组已经有序的数据,经过建堆,数据变得更无序了。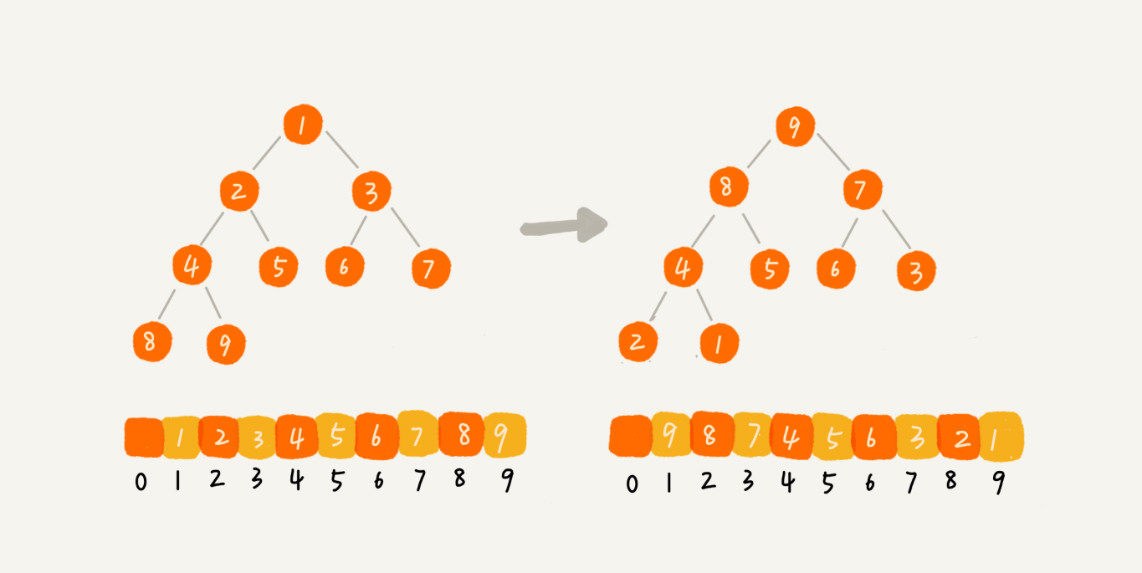
堆的应用
堆有几个非常重要的应用:优先级队列,求TopK和求中位数。
堆的应用一:优先级队列
队列是先进先出,不过在优先级队列里,出队顺序不是先进先出,而是按照优先级来,优先级最高的最先出队。
一个堆就可以看作是一个优先级队列。
有很多数据结构和算法都依赖它,比如霍夫曼编码,图的最短路径,最小生成树算法等等。很多语言都提供了优先级队列的实现,比如Java的PriorityQueue,C++的priority_queue等。
1.合并有序小文件
假设有100个小文件,每个文件的大小是100MB,每个文件中存储的都是有序的字符串。希望将这些100个小文件合并成一个有序的大文件。 这里就会用到优先级队列。
从小文件中取出字符串放入小订堆汇总,堆顶的元素,也就是优先级队列队首的元素就是最小的字符串。将这个字符串放入到大文件中,并将其从堆中删除。再从小文件中取出下一个字符串,放入到堆中。循环这个过程,就可以将100个小文件依次放入到大文件中。
其中,删除堆顶数据和往堆中插入数据的时间复杂度都是O(logn)。
2.高性能定时器
堆的应用二:利用堆求TopK
TopK问题分为两类,一类是针对静态数据集合,就是数据集合事先确定,不会再变。另一类是针对动态数据集合,就是数据集合事先并不确定,有数据动态地加入到集合中。
针对静态数据,如何在一个包含n个数据的数组中,查找前K大数据呢?我们可以维护一个大小为K的小顶堆,顺序遍历数组,从数组中取出数据与堆顶元素比较。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理,继续遍历数组。这样等数组中的数据都遍历完之后,堆中的数据就是前K大数据了。遍历数组需要O(n)的时间复杂度,一次堆化操作需要O(logK)的时间复杂度,所以最坏情况下,n个元素都入堆一次,时间复杂度就是O(nlogK)。
动态数据求得Top K就是实时Top K。一个数据集合中有两个操作,一个是添加数据,另一个询问当前的前K大数据。
实际上,我们可以一直都维护一个K大小的小顶堆,当有数据被添加到集合中时,我们就拿它与堆顶的元素对比。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理。这样,无论任何时候需要查询当前的前K大数据,都可以立刻返回。
堆的应用三:利用堆求中位数
对于静态数据,中位数是固定的,可以先排序取中间就是中位数,面对动态数据集合,中位数不断变动,如果再用先排序的方法,效率就不高了。借助堆这种数据结构,不用排序,就可以非常高效地实现求中位数操作。
需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。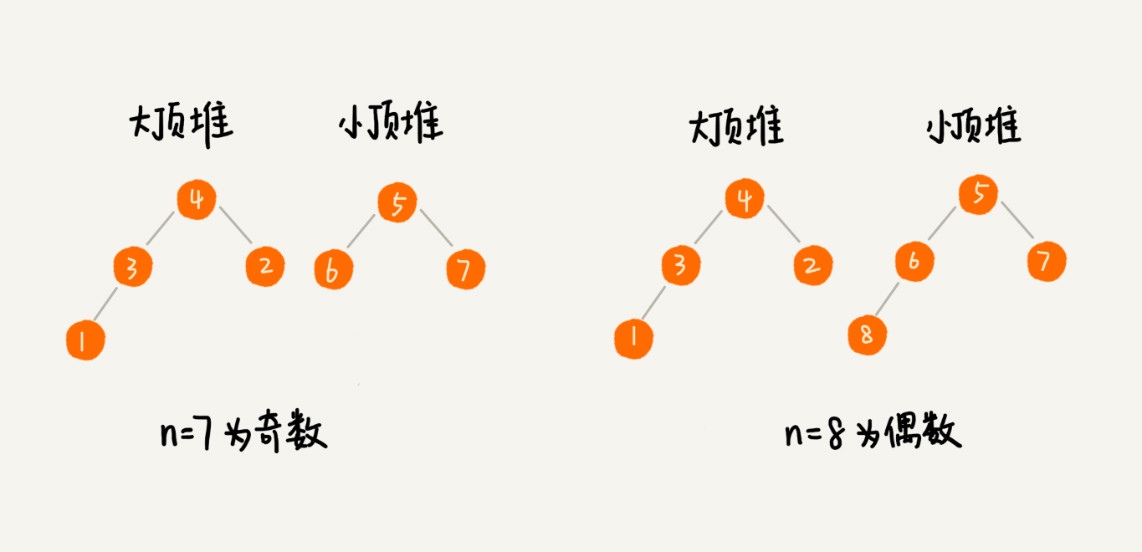
大顶堆的堆顶即为要找的中位数。
当新添加一个数据的时候,如果新加入的数据小于等于大顶堆的堆顶元素,就将这个新数据插入到大顶堆;否则,就将这个新数据插入到小顶堆。
这个时候就有可能出现,两个堆中的数据个数不符合约定的情况:如果n是偶数,两个堆中的数据个数都是n / 2;如果n是奇数,大顶堆有 n / 2 +1 个数据,小顶堆有 n / 2 个数据。这个时候,可以从一个堆中不停地将堆项元素移动到另一个堆,通过这样的调整,来让两个堆中的数据满足约定。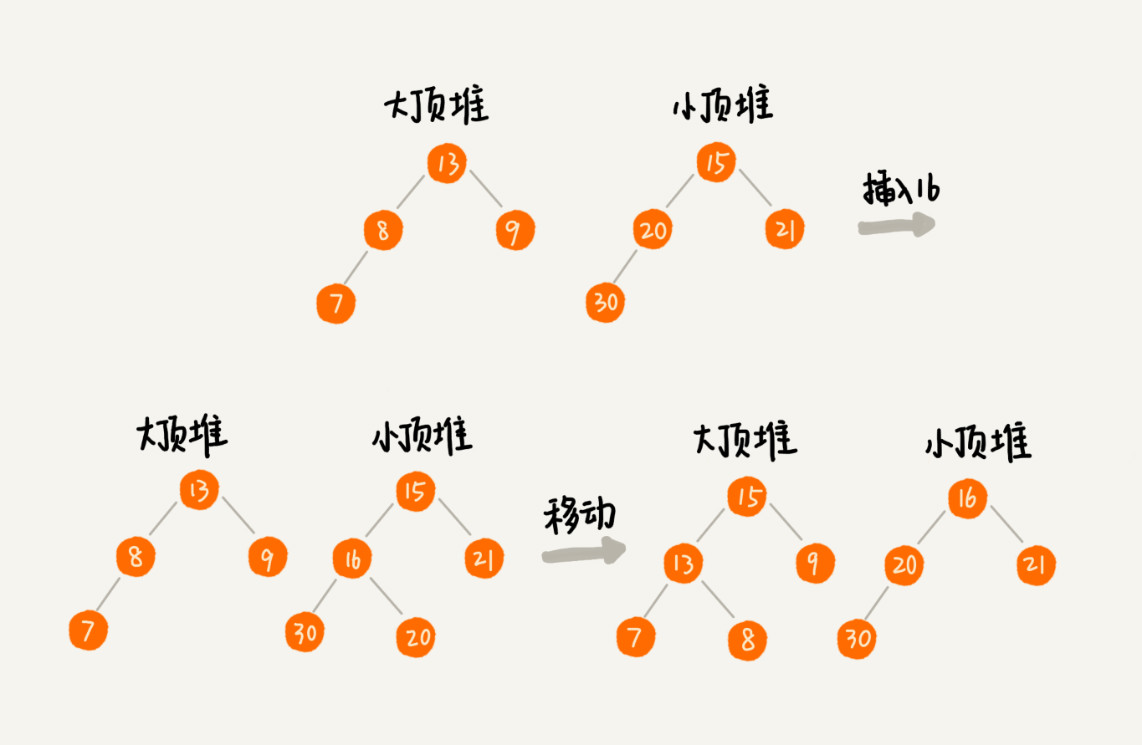
插入数据因为需要涉及堆化,所以时间复杂度为O(logn), 但是求中位数只需要返回大顶堆的堆顶元素,时间复杂度为O(1)。
通过类似的方法可以求任意百分位值。