图的概念
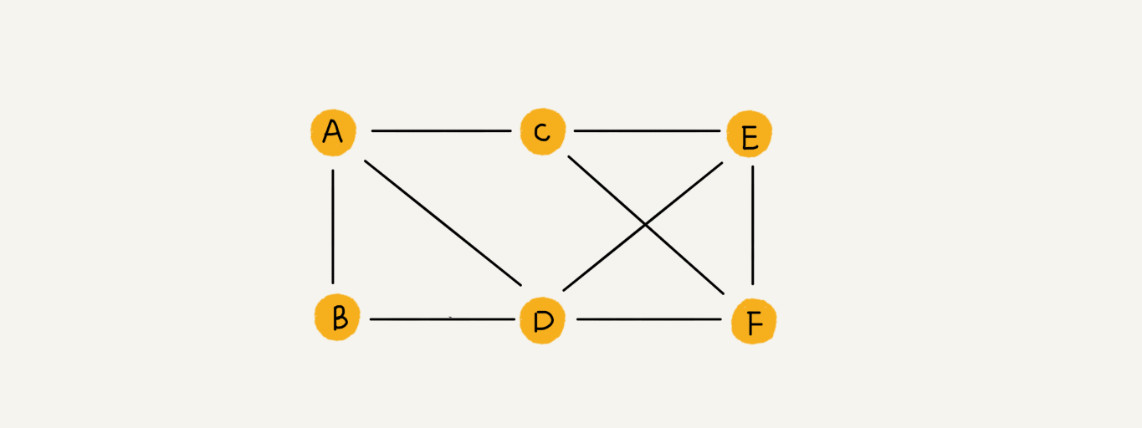
无向图,两者之间建立一条边,称为顶点的度。就是跟顶点相连接的边的条数。
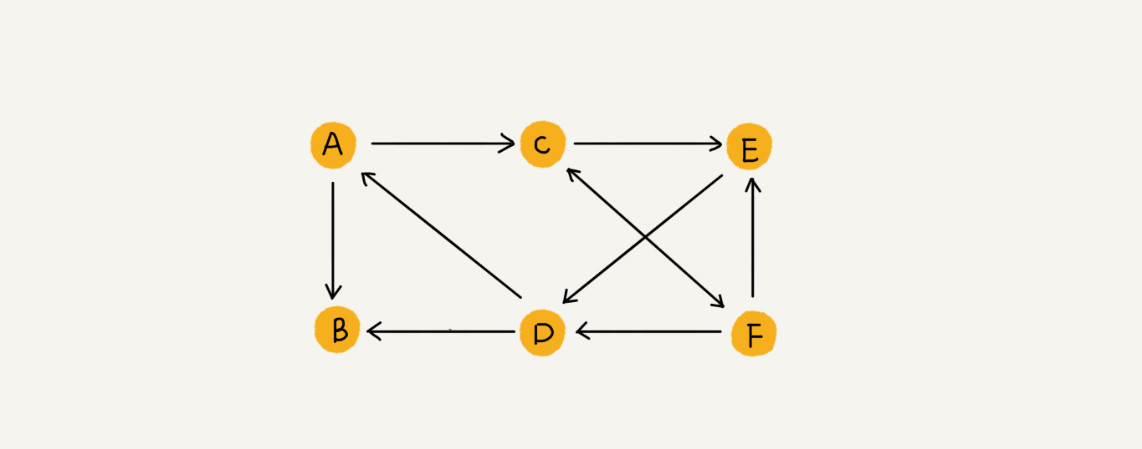
有向图,在有向图中把度分为入度和出度。
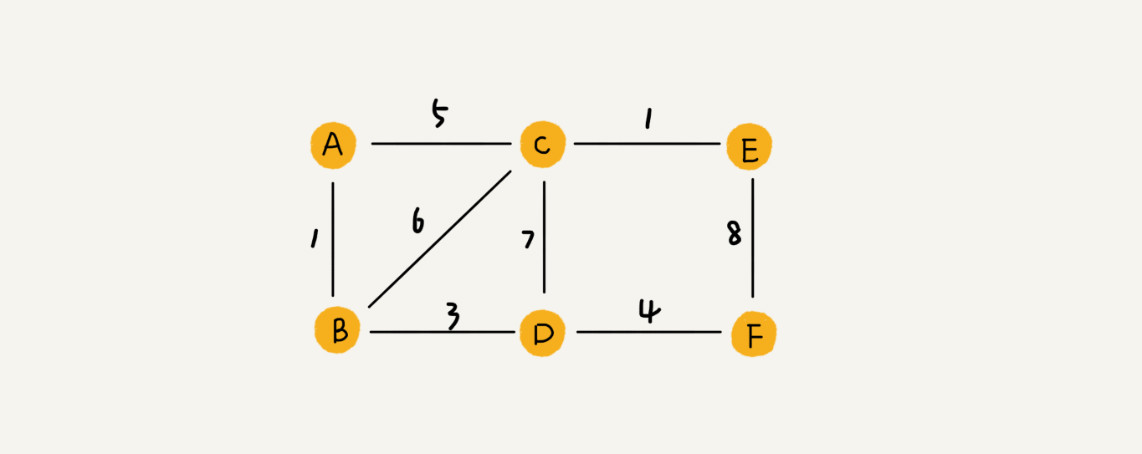
带权图,每条边都有一个权重。
图的存储方法
邻接矩阵存储法
图最直观的存储方法就是邻接矩阵。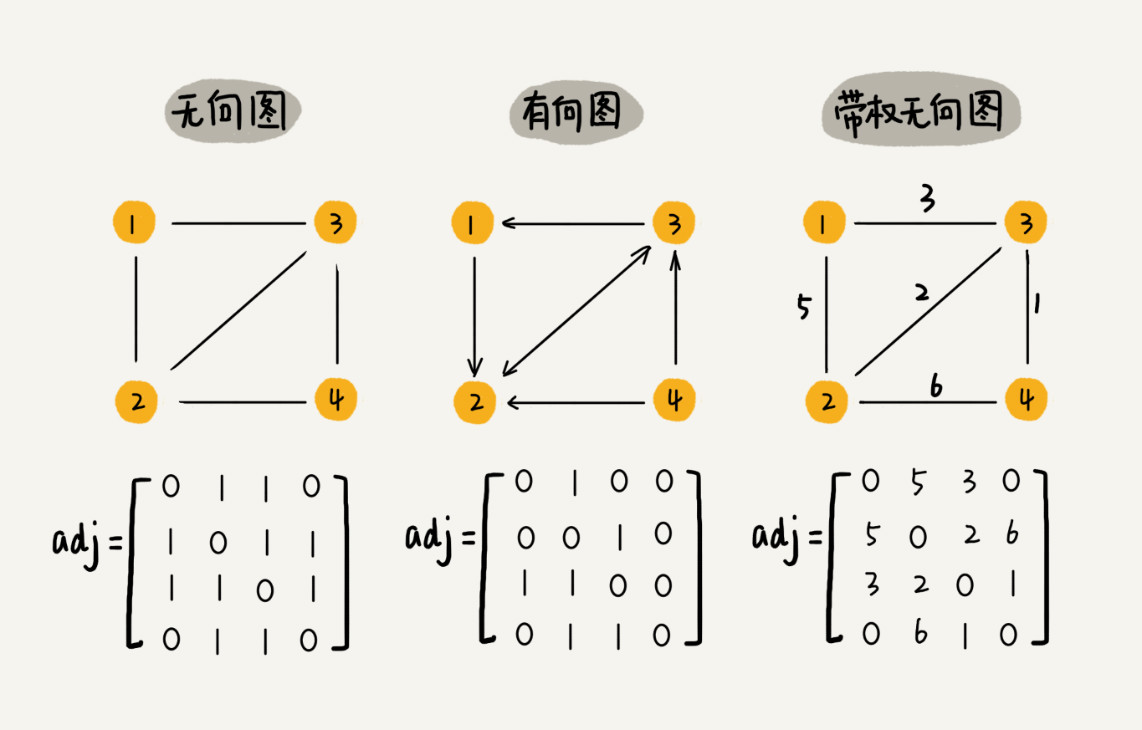
用邻接表来表示一个图虽然简单直观,比较浪费存储空间。如果存储的是稀疏图,就更加浪费空间了。
邻接矩阵的优点在于简单直接,在获取两个顶点关系时非常高效,其次还方便计算。
邻接表存储方法
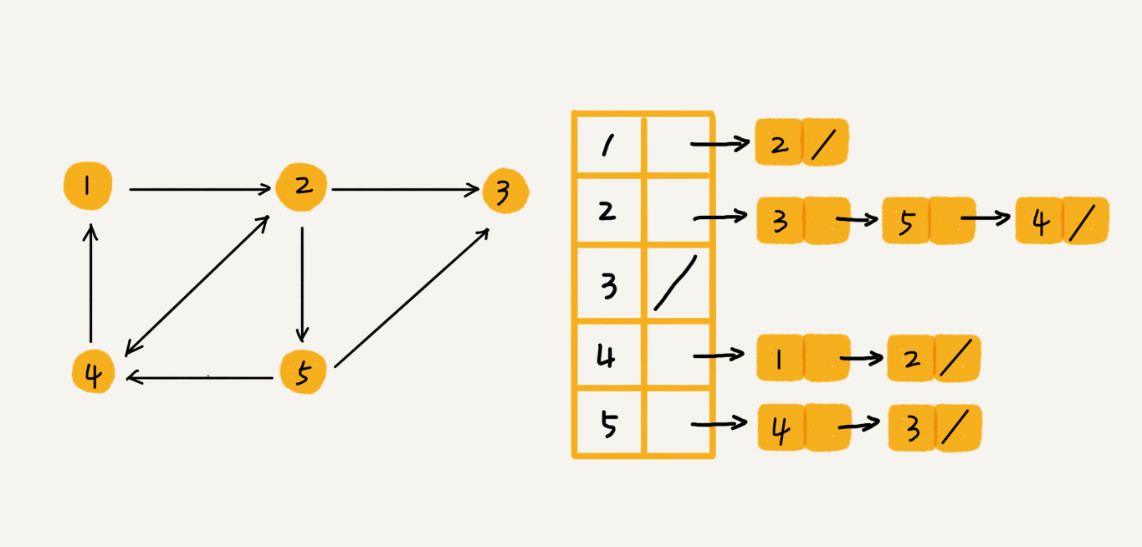
邻接表存储起来比较节省空间,使用起来比较耗时间。
如果链过长,为了提高查找效率,可以将链表换成其他更加高效的数据结构,比如红黑树。也可以使用其他动态数据结构比如跳表和散列表。
存储微博关系
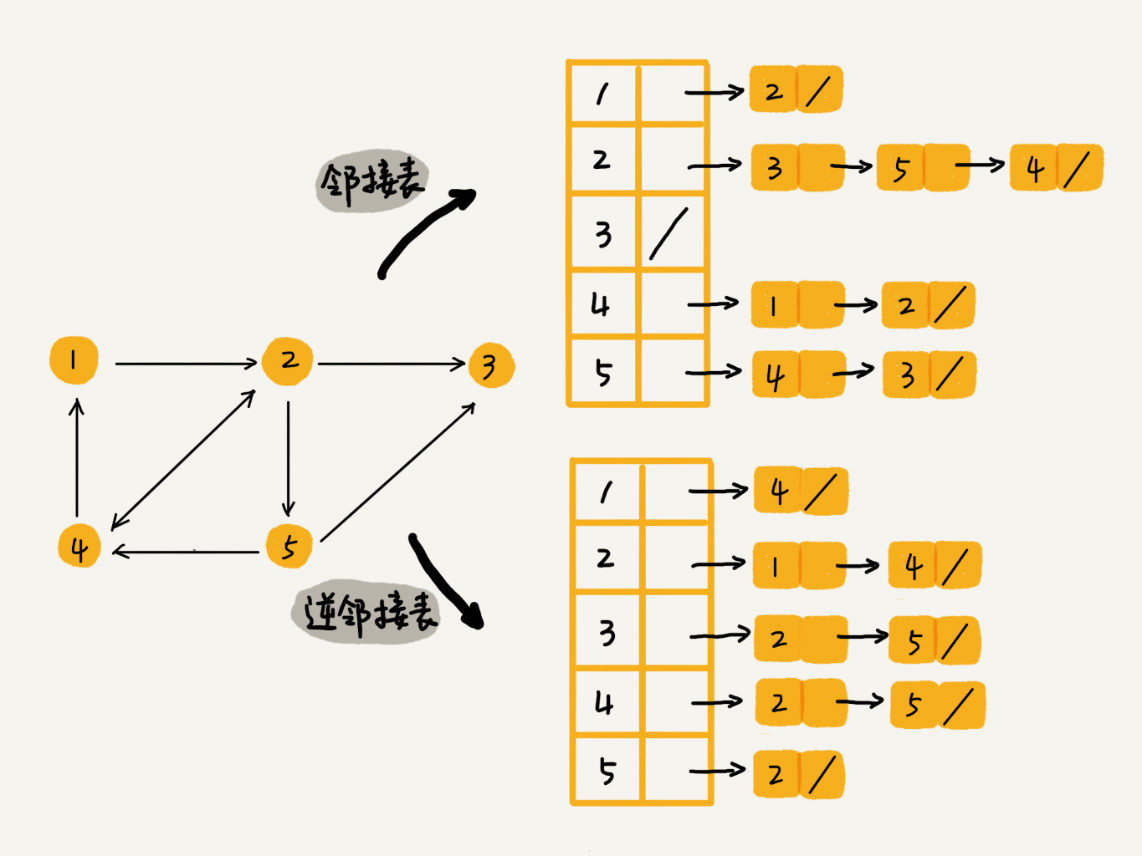
邻接表中存储了用户的关注关系,逆邻接表中存储的是用户的被关注关系。
搜索算法
广度优先搜索(BFS)
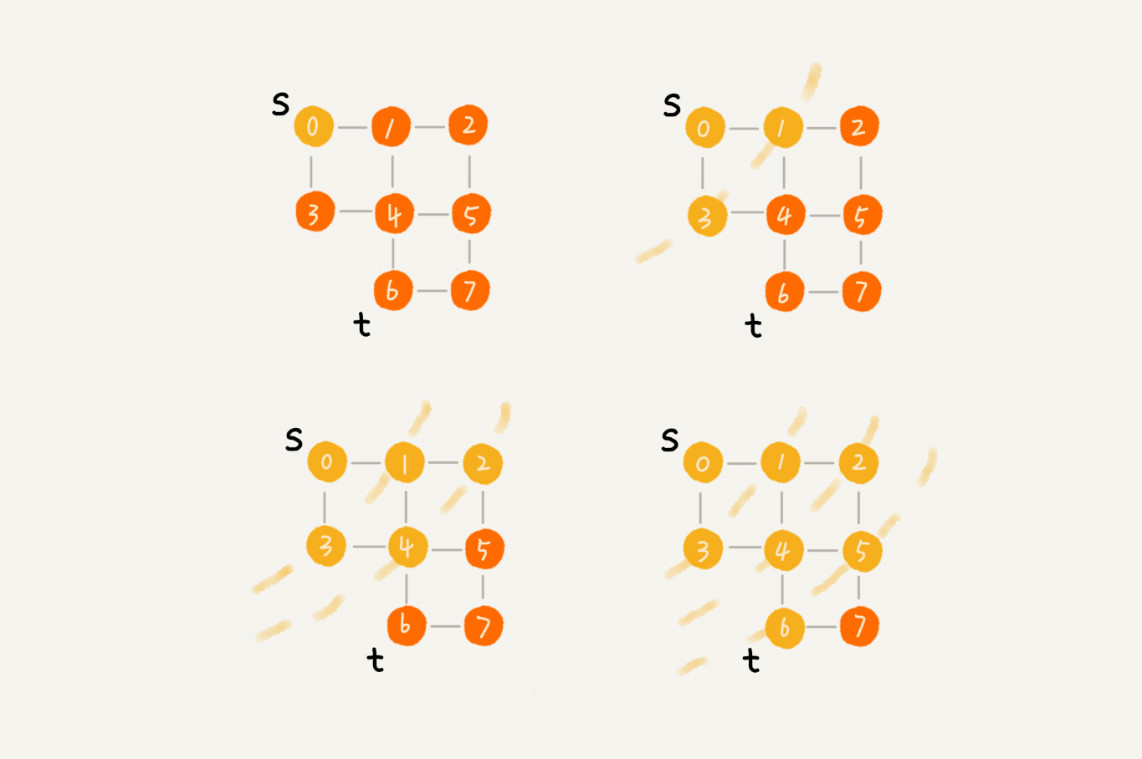
借助队列。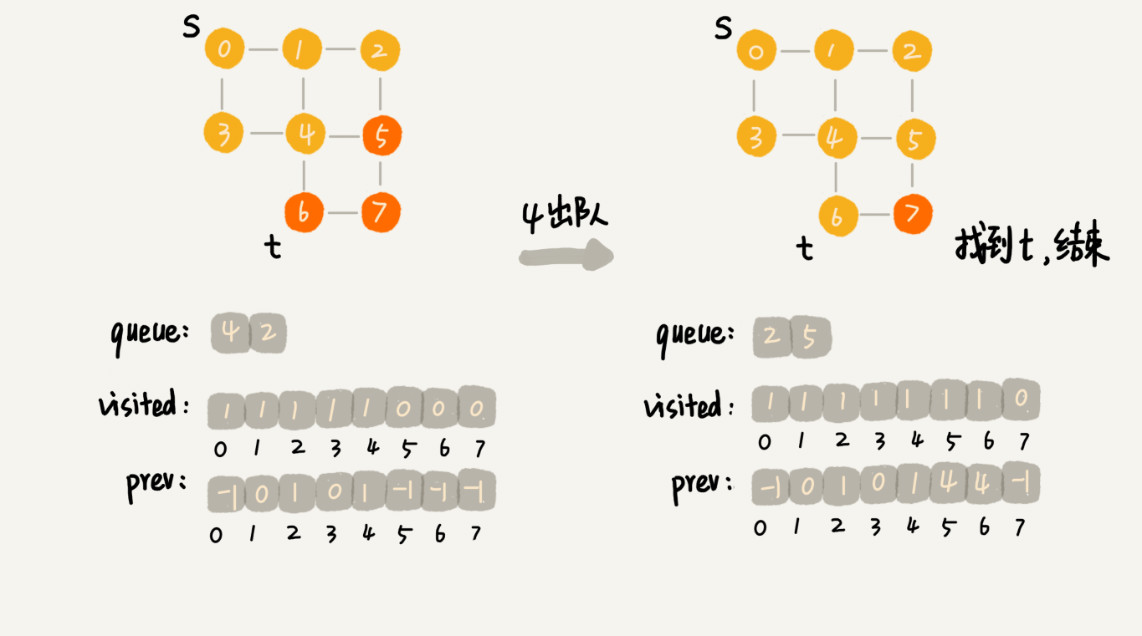
广度优先搜索的时间复杂度是O(V+E),V表示顶点的个数,E表示边的个数。
广度优先搜索的控件消耗主要在几个辅助变量visited数组、queue队列、prev数组上。这三个存储空间的大小都不会超过顶点的个数。所以空间复杂度是O(V)。
深度优先搜索(DFS)
借助栈。
深度优先搜索算法的时间复杂度是O(E),E表示边的个数。
深度优先搜索算法的消耗内存主要是visited、 prev 数组和递归调用栈。visited、 prev 数组的大小跟顶点的个数V成正比,递归调用栈的最大深度不会超过顶点的个数,所以总的空间复杂度就是O(V)。