Java
Java多态
其核心之处就在于对父类方法的改写或对接口方法的实现,以取得在运行时不同的执行效果。要使用多态,在声明对象时就应该遵循一条法则:声明的总是父类类型或接口类型,创建的是实际类型。
List list =newArrayList(); ✔️
ArrayList list =newArrayList(); ❎
在定义方法参数时也通常总是应该优先使用父类类型或接口类型。
publicvoid doSomething(List list);✅
publicvoid doSomething(ArrayList list);❎
这样声明最大的好处在于结构的灵活性:假如某一天我认为ArrayList的特性无法满足我的要求,我希望能够用LinkedList来代替它,那么只需要在对象创建的地方把new ArrayList()改为new LinkedList即可,其它代码一概不用改动。
虚拟机会在执行程序时动态调用实际类的方法,它会通过一种名为动态绑定(又称延迟绑定)的机制自动实现,这个过程对程序员来说是透明的。
Java异常处理
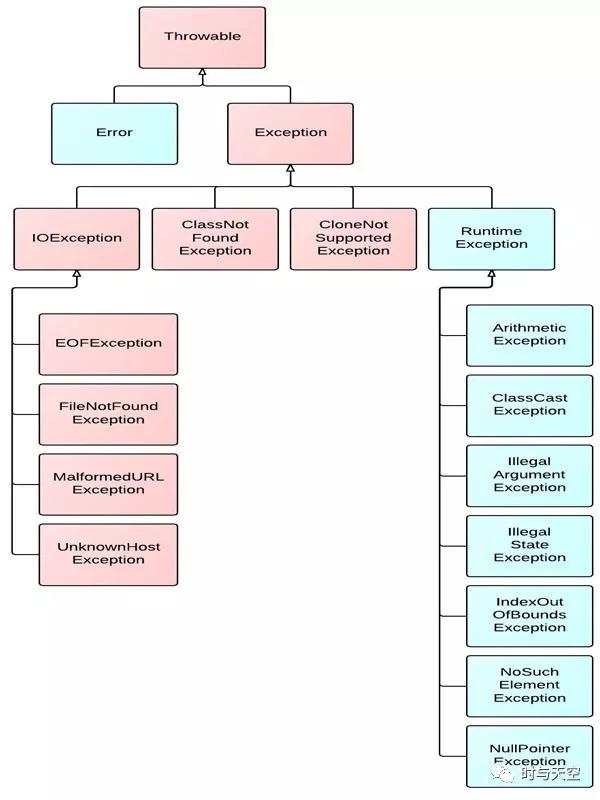
Throwable 是所有异常类型的基类,Throwable 下一层分为两个分支,Error 和 Exception.
Error 描述了 JAVA 程序运行时系统的内部错误,通常比较严重,除了通知用户和尽力使应用程序安全地终止之外,无能为力,应用程序不应该尝试去捕获这种异常。通常为一些虚拟机异常,如 StackOverflowError 等。
Exception 类型下面又分为两个分支,一个分支派生自 RuntimeException,这种异常通常为程序错误导致的异常;另一个分支为非派生自 RuntimeException 的异常,这种异常通常是程序本身没有问题,由于像 I/O 错误等问题导致的异常,每个异常类用逗号隔开。
受查异常
受查异常会在编译时被检测。如果一个方法中的代码会抛出受查异常,则该方法必须包含异常处理,即 try-catch 代码块,或在方法签名中用 throws 关键字声明该方法可能会抛出的受查异常,否则编译无法通过。
private static void readFile(String filePath) throws IOException {
非受查异常不会在编译时被检测。JAVA 中 Error 和 RuntimeException 类的子类属于非受查异常,除此之外继承自 Exception 的类型为受查异常。
处理RuntimeException的原则是:如果出现RuntimeException,那么一定是程序员的错误。受检查的异常(IOException等):这类异常如果没有try……catch也没有throws抛出,编译是通不过的。这类异常一般是外部错误,例如文件找不到、试图从文件尾后读取数据等,这并不是程序本身的错误,而是在应用环境中出现的外部错误。
Java数据类型
8种基本数据类型(所占字节数)
byte(1) char(2) short(2) int(4) float(4) double(8) long(8) boolean(1)
boolean类型比较特别,多个boolean可能共同占用一个字节。
String
String不是基本数据类型,是引用类型,底层用char数组实现的,因为String是final类,在java中被final修饰的类不能被继承,因此String不可以被继承。
Java的IO
字节流与字符流
首先明确“字节(Byte)”和“字符(Character)”的大小:
1 byte = 8 bit
1 char = 2 byte = 16 bit (Java默认UTF-16编码)
总而言之,一切都是字节流,其实没有字符流这个东西。字符只是根据编码集对字节流翻译之后的产物。面向字节流的InputStream和OutputStream
面向字符的Reader和Writer,即为字节流继承于InputStream和OutputStream,字符流继承于InputStreamReader和OutputStreamWriter。
字节流转字符流
字节输入流转字符输入流通过InputStreamReader实现,该类的构造函数可以传入InputStream对象。字节输出流转字符输出流通过OutputStreamWriter实现,该类的构造函数可以传入OutputStream对象。
将java对象序列化到文件
在java中能够被序列化的类必须先实现Serializable接口,该接口没有任何抽象方法只是起到一个标记作用。当试图对一个对象进行序列化的时候,如果该对象没有实现 Serializable 接口,将抛出NotSerializableException
serialVersionUID: 字面意思上是序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量
显式地定义serialVersionUID有两种用途:
1、 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
2、 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
Java容器
容器Container,和Array的最大区别就是它们的长度都是自动变化的,根本无需你干预。
Container 从总体上来看分为两类,一类叫做集合Collection ,另一类则叫做映射Map。
区别很简单在Map中,对象必须是成对存放的,这个对就叫做key-value,而集合则不是。集合又分为集Set、序列List和队列Queue。向Map中添加元素的方法是put(K key, V value),而向Collection中添加则是add(E e)。
基本结构
集Set、序列List和队列Queue 之所以说他们属于Collection,是因为他们都实现了Collection这个interface。并且他们也不是“实现类”,而是interface,他们并不能直接使用。
对集合排序
凡是对集合的操作,应该保持一个原则就是能用JDK中的API就用JDK中的API,比如排序算法不应去用冒泡或者选择排序,而是首先想到用Collections集合工具类。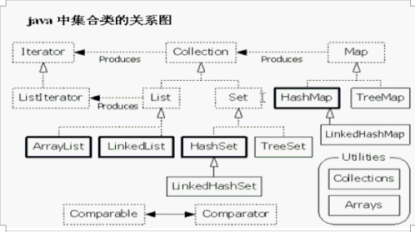
Collection常用的方法:
集合的实现类
List:ArrayList(数组实现) LinkedList(链表实现)
Set:HashSet TreeSet LinkedHashMap (三种与Map实现类相同)
Set的特点是元素不能重复,在元素添加过程中,最重要的一个步骤就是进行对比,将对象通过Hash后对比速度飞起。
Queue:ArrayDeque(双端队列) PriorityQueue(保证最小的在顶上,并不是全部排序)
集合的安全性问题
ArrayList,HashSet,HashMap不是没有加锁,显然都是线程不安全的。
在集合中 Vector和 HashTable倒是线程安全的。你打开源码会发现其实就是把各自核心方法添加上了synchronized关键字
Map
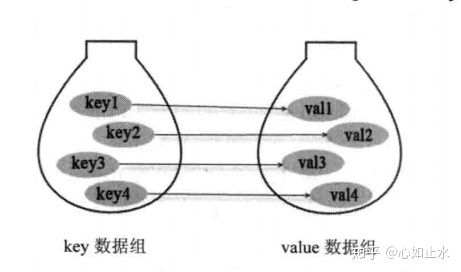
单看Key,不就是Set吗,Set就是用Map实现的,可以说Set是Map的一种特殊应用。Map中也有一个叫做KeySet()的方法,直接返回一个Set。
Java多线程
创建的两种方式
java.lang.Thread类的实例就是一个线程但是它需要调用java.lang.Runnable接口来执行,由于线程类本身就是调用的Runnable接口所以你可以继承java.lang.Thread类或者直接实现Runnable接口来重写run()方法实现线程。
sleep和wait
最大的不同是在等待时wait会释放锁,而sleep 一直持有锁。wait通常被用于线程间交互, sleep通常被用于暂停执行。
synchronized和volatile关键字
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1 )保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2 )禁止进行指令重排序。
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取,精确地说就是,编译优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。
synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
两者的区别:
1.voltile仅能使用在变量级别;synchronized 则可以使用在变量、方法、和类级别的。
2.volatile仅能实现变量的修改可见性,并不能保证原子性;synchronized 则可以保证变量的修改可见性和原子性。
3.volatile不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。
4.volatile标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化。
一道线程安全的题

上述代码执行后输出的结果不等于1000。
在java的内存模型中每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立-个变量副本 ,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前) ,自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。
也就是说上面主函数中开启了1000 个子线程,每个线程都有一个变量副本,每个线程修改变量只是临时修改了自己的副本,当线程结束时再将修改的值写入在主内存中, 这样就出现了线程安全问题。因此结果就不可能等于1000了。一般都会小于1000。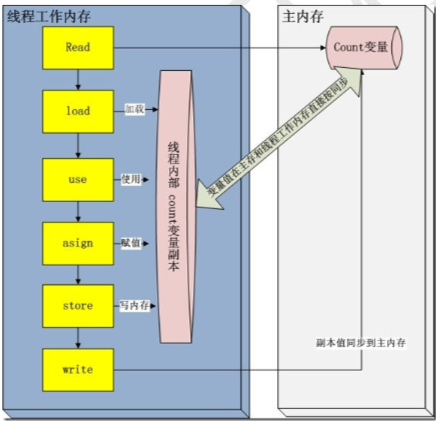
线程池与使用
线程池就是事先将多个线程对象放到一个容器中,当使用的时候就不用new线程而是直接去池中拿线程即可,节省了开辟子线程的时间,提高的代码执行效率。
Java SE高级
Java反射
Java中的反射首先是能够获取到Java中要反射类的字节码.获取字节码有三种方法,1.Class.forName(className) 2.类名.class 3.this.getClass(). 然后将字节码中的方法,变量,构造函数等映射成相应的Method. Filed, Constructor 等类,这些类提供了丰富的方法可以被我们所使用。
Java动态代理
创建对象的过程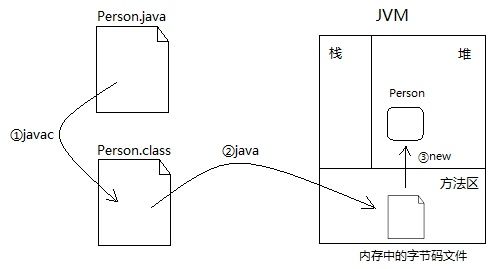
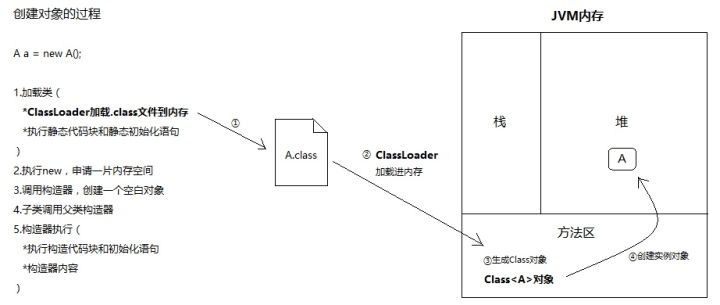
创建一个实例,最关键的就是得到对应的Class对象。
代理类和目标类理应实现同一组接口。之所以实现相同接口,是为了尽可能保证代理对象的内部结构和目标对象一致,这样我们对代理对象的操作最终都可以转移到目标对象身上,代理对象只需专注于增强代码的编写。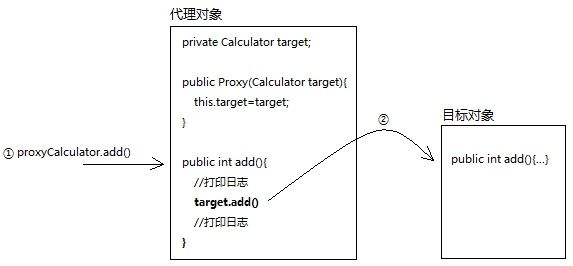
动态代理的使用场景:
(1)设计模式中有一个设计原则是开闭原则,是说对修改关闭对扩展开放,我们在工作中有时会接手很多前人的代码,里面代码逻辑让人摸不着头脑
,这时就很难去下手修改代码,那么这时我们就可以通过代理对类进行增强。
(2)我们在使用RPC框架的时候,框架本身并不能提前知道各个业务方要调用哪些接口的哪些方法 。那么这个时候,就可用通过动态代理的方式来建立一个中间人给客户端使用,也方便框架进行搭建逻辑,某种程度上也是客户端代码和框架松耦合的一种表现。
(3)Spring的AOP机制就是采用动态代理的机制来实现切面编程。

Java中的设计模式
设计模式供分为三大类:
1、创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式。原型模式。
2、结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
3、行为型模式,共十一种:策略模式,模板方法模式、观察者模式,迭代子模式、责任链模式、命令模式、 备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。