二分查找
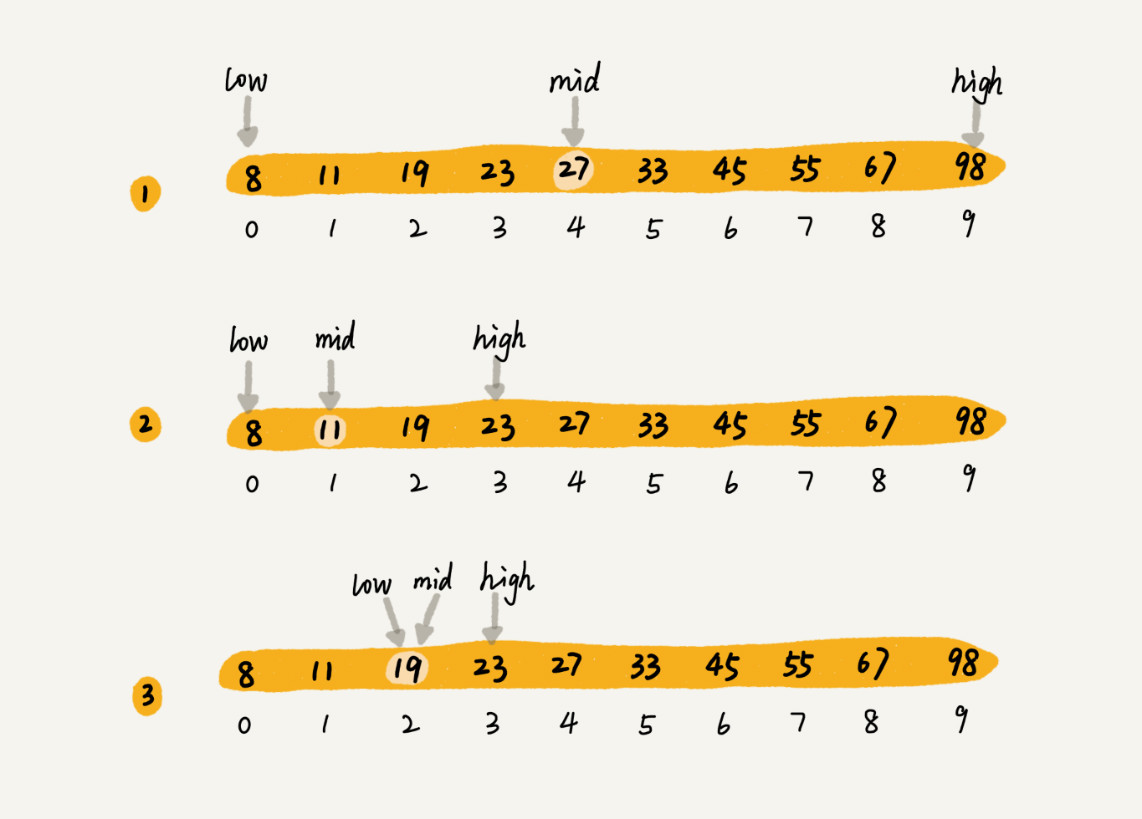
二分查找针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为0。
惊人的查找速度O(logn)。比如n等于2的32次方,大约是32亿,但是在42亿个数据中用二分查找一个数据,最多需要比较32次。常量级时间复杂度的算法有时候可能还没有O(logn)的算法执行效率高。
二分查找的递归与非递归实现
对于最简单的情况,即不存在重复数据的情况。
三个容易出错的地方:
1.循环退出条件
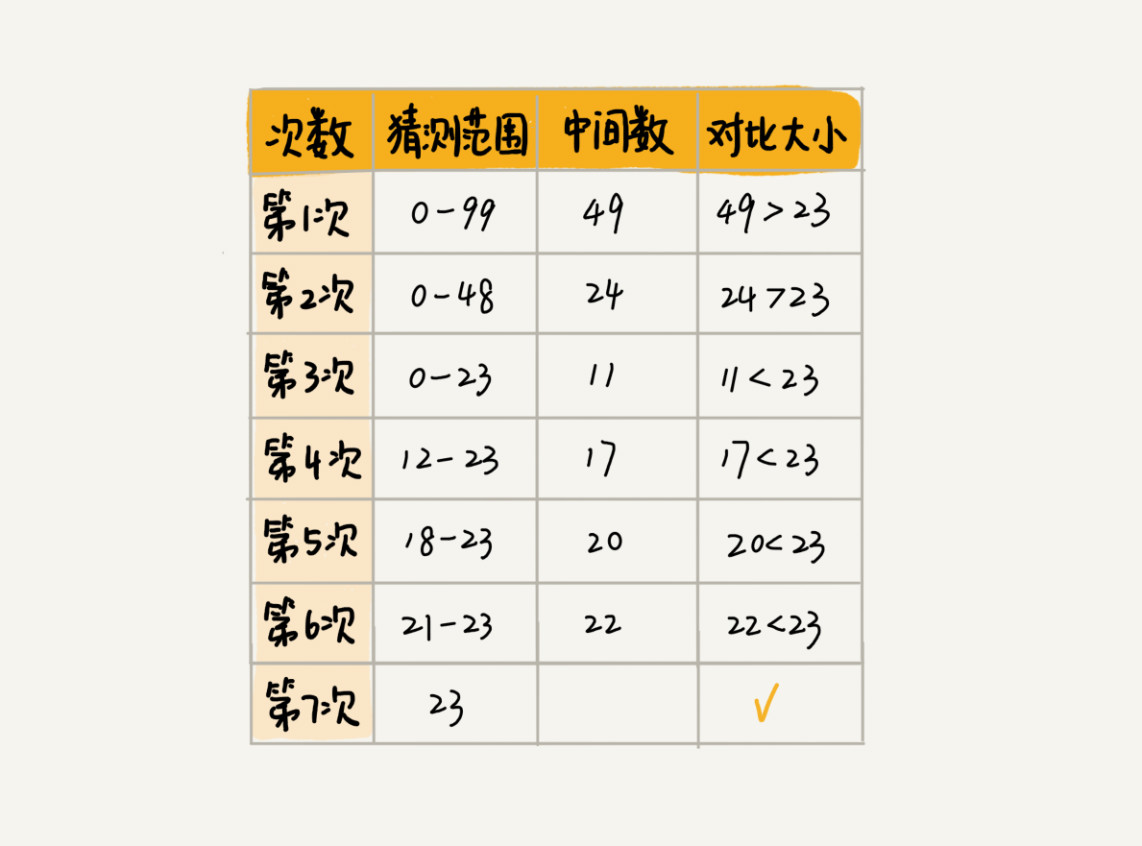
是low<=high,而不是low<high。
2.mid的取值
实际上,mid=(ow+high)/2这种写法是有问题的。因为如果low和high比较大的话,两者之和就有可能会溢出。改进的方法是将md的计算方式写成low+(high-low)/2。更进一步,如果要将性能优化到极致的话,我们可以将这里的除以2操作转化成位运算low+(high-low)>>1)。因为相比除法运算来说,计算机处理位运算要快得多。
3.low和hign的更新
low=md+1,high=mid-1。注意这里的+1和-1,如果直接写成low=mid或者high=mid,就可能会发生死循环。比如,当high=3,low=3时,如果a3]不等于value,就会导致一直循环不退出。
二分查找除了用循环来实现,还可以用递归来实现。
二分查找应用场景的局限性
首先,二分查找依赖的是顺序表结构,简单说就是数组。
其次,二分查找针对的是有序数据。如果数据没有序,我们需要先排序。二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用。
再次,数据量太小不适合二分查找。如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。只有数据量比较大时,二分查找的优势才会比较明显。如果数据之间的比较操作非常耗时,不管数据量大小,都推荐使用二分查找。
最后,数据量太大也不适合二分查找。二分查找的底层需要依赖数组,需要有大量的连续的内存空间,对于1gb的数据,需要有1gb连续内存空间。
虽然大部分情况下,用二分查找可以解决的问题,用散列表、二叉树都可以解决,但是不论是散列表还是二叉树都会需要比较多的额外的内存空间。二分查找底层依赖的是数组,除了数据本身之外,不需要额外存储其他信息,是最省内存空间的存储方式。
二分查找简单情况的变形

查找第一个值等于给定值的元素
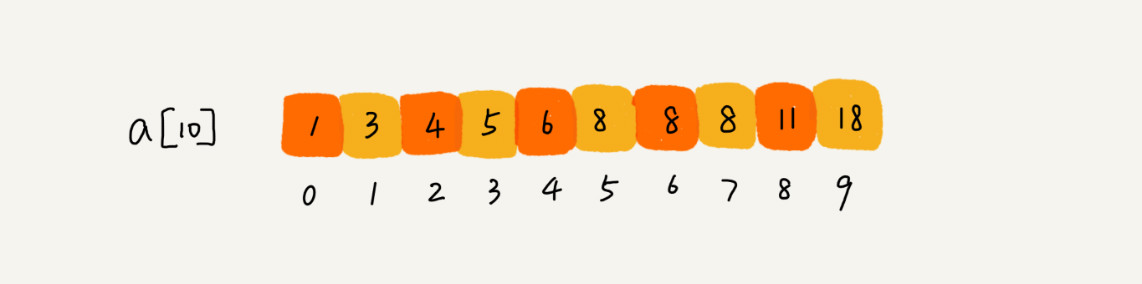
对于之前简单情况的代码进行一些变形。
查找的是任意一个值等于给定值的元素,当a[mid]等于要查找的值时,a[mid]就是我们要找的元素,此时需要确认是否是第一个值等于给定值的元素。经检查发现a[mid]前面一个元素a[mid-1]也等于value,那么说明此时的a[mid]肯定不是第一个值等于给定值的元素,就更新high=mid-1。
变体二 查找最后一个值等于给定值的元素
同理可得
变体三 查找第一个大于等于给定值的元素

思路类似
变体四 查找最后一个小于等于给定值的元素
类似
快速定位出一个ip地址归属地
首先将ip地址排序,将问题转化为在有序数组中,查找最后一个小于等于某个给定值的元素。