Item2Vec Microsoft
ITEM2VEC: NEURAL ITEM EMBEDDING FOR COLLABORATIVE FILTERING
ABSTRACT
The method is capable of inferring item-item relations even when user information is not available.
INTRODUCTION AND RELATED WORK
many recommendation algorithms are focused on learning a low dimensional embedding of users and items simultaneously ,computing item similarities is an end in itself .
The single item recommendations are different than the more “traditional” user-to-item recommendations because they are usually shown in the context of an explicit user interest in a specific item and in the context of an explicit user intent to purchase. Therefore, single item recommendations based on item similarities often have higher Click-Through Rates (CTR) than user-to-item recommendations and consequently responsible for a larger share of sales or revenue.
item similarities are used in online stores for better exploration and discovery and improve the overall user experience.
ITEM2VEC – SGNS FOR ITEM SIMILARITY
Since some scenarios could not provide information about multiple sets of items might belong to the same user .user-item CF may not work well.
By moving from sequences to sets, the spatial / time information is lost. We choose to discard this information, since in this paper, we assume a static environment where items that share the same set are considered similar, no matter in what order / time they were generated by the user.
Since we ignore the spatial information, we treat each pair of items that share the same set as a positive example. This implies a window size that is determined from the set size. 这里意思是在训练时,窗口不像w2v中是定长的,而是一个变长的窗口,根据一个订单中物品的大小来动态确定。Specifically, for a given set of items, the objective from Eq. (1) is modified as follows: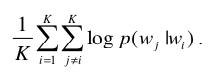
Another option is to keep the objective in w2v as is, and shuffle each set of items during runtime. In our experiments we observed that both options perform the same.
In this work, we used u_i_ as the final representation for the i-th item and the affinity between a pair of items is computed by the cosine similarity.
EXPERIMENTAL
Datasets
The first dataset is user-artist data that is retrieved from the Microsoft Xbox Music service. This dataset consist of 9M events. Each event consists of a user-artist relation, which means the user played a song by the specific artist. The dataset contains 732K users and 49K distinct artists.
The second dataset contains orders of products from Microsoft Store. An order is given by a basket of items without any information about the user that made it. Therefore, the information in this dataset is weaker in the sense that we cannot bind between users and items. The dataset consist of 379K orders (that contains more than a single item) and 1706 distinct items.
Systems and parameters
We applied item2vec to both datasets. The optimization is done by stochastic gradient decent. We ran the algorithm for 20 epochs. We set the negative sampling value to N=15 for both datasets. The dimension parameter m was set to 100 and 40 for the Music and Store datasets, respectively. We further applied subsampling with ρ values of 10−5 and 10−3 to the Music and Store datasets, respectively. The reason we set different parameter values is due to different sizes of the datasets.
论文解读
一个物品集合被视作自然语言中的一个段落,物品集合的基本元素-物品等价于段落中的单词。因此在论文中,一个音乐物品集合是用户对某歌手歌曲的播放行为,一个商品集合是一个订单中包含的所有商品。
从自然语言序列迁移到物品集合,丢失了空间/时间信息,还无法对用户行为程度建模(喜欢和购买是不同程度的强行为)。好处是可以忽略用户-物品关系,即便获得的订单不包含用户信息,也可以生成物品集合。而论文的结论证明,在一些场景下序列信息的丢失是可忍受的。
知乎上的实践思路
https://zhuanlan.zhihu.com/p/28491088
爬取的训练数据是豆瓣网友的电影收藏夹(类比于网易云的歌单)。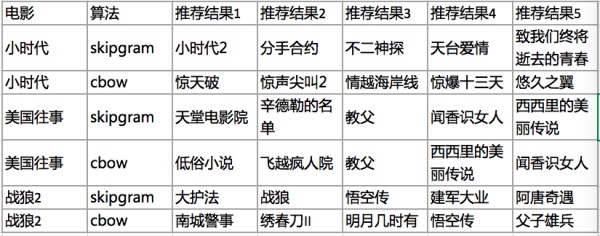
从结果中可以观察出一些有意思的结论。战狼2是最近刚出的电影(此文作于2017/08),包含战狼2的大多是“暑期国产电影合集”,“2017年不得不看的国产电影“这类豆列;美国往事属于经典老片,训练语料足够多,skipgram和cbow的推荐结果各有千秋;小时代在豆瓣中属于不受待见的一类电影,包含小时代的豆列较少,skipgram的推荐结果优于cbow。
Youtube
Deep Neural Networks for YouTube Recommendations
ABSTRACT
Three major changllenging :(1)Scale,(2)Freshness,(3)Noise.
SYSTEM OVERVIEW
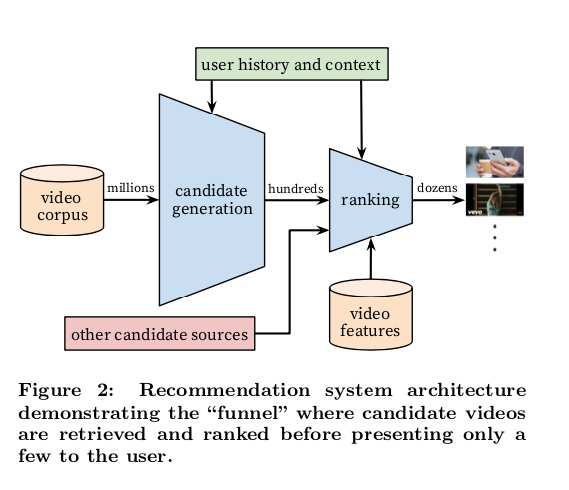
CANDIDATE GENERATION
During candidate generation, the enormous YouTube corpus is winnowed down to hundreds of videos that may be relevant to the user .
Recommendation as Classification

compared to w2v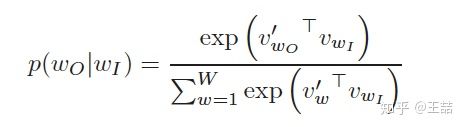
you can see Youtube have two embeddings.
Although explicit feedback mechanisms exist on YouTube (thumbs up/down, in-product surveys, etc.) They use the implicit feedback of watches to train the model, where a user completing a video is a positive example. This choice is based on the orders of magnitude more implicit user history available, allowing They to produce recommendations deep in the tail where explicit feedback is extremely sparse.
Efficient Extreme Multiclass
To efficiently train such a model with millions of classes, they rely on a technique to sample negative classes from the background distribution (“candidate sampling”) and then correct for this sampling via importance weighting ,For each example the cross-entropy loss is minimized for the true label and the sampled negative classes.
negative sample?
In practice several thou- sand negatives are sampled, corresponding to more than 100 times speedup over traditional softmax.
At serving time they need to compute the most likely N classes (videos) in order to choose the top N to present to the user. Scoring millions of items under a strict serving latency of tens of milliseconds requires an approximate scoring scheme sublinear in the number of classes.
The classifier described here uses a similar approach. the scoring problem reduces to a nearest neighbor search in the dot product space for which general purpose libraries can be used .
Model Architecture
A user’s watch history is represented by a variable-length sequence of sparse video IDs which is mapped to a dense vector representation via the embeddings.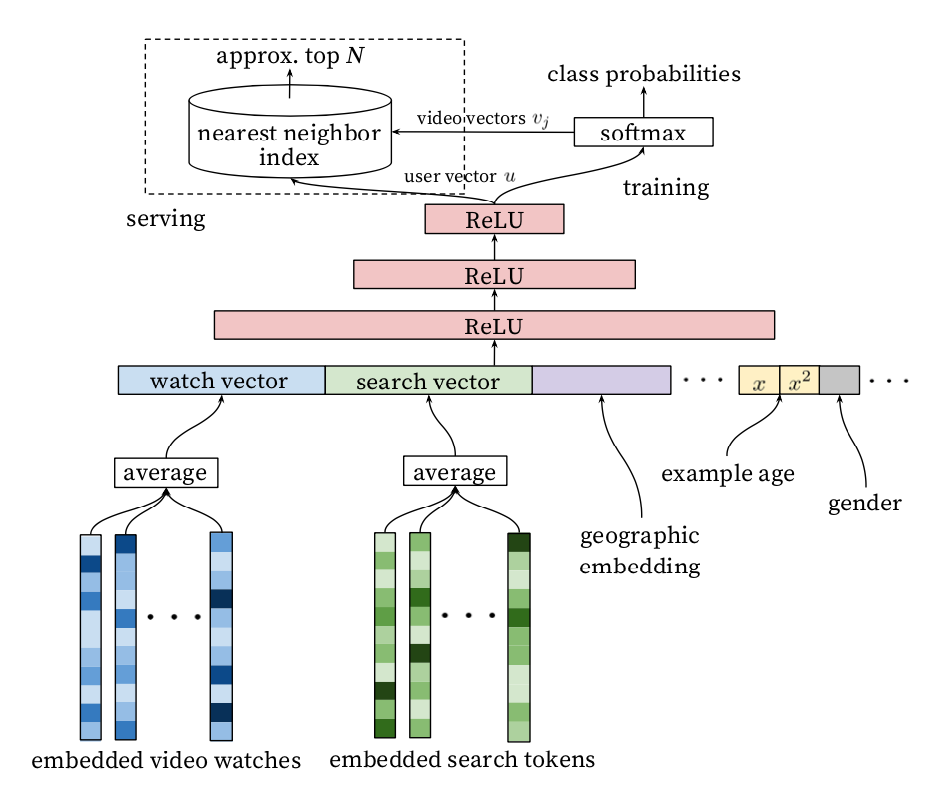
Heterogeneous Signals
Search history is treated similarly to watch history - each query is tokenized into unigrams and bigrams and each token is embedded. Once averaged, the user’s tokenized, em- bedded queries represent a summarized dense search history.
Demographic features are important for providing priors so that the recommendations behave reasonably for new users.
The user’s geographic region and device are embedded and concatenated. Simple binary and continuous features such as the user’s gender, logged-in state and age are input directly into the network as real values normalized to [0, 1].
“Example Age” Feature
Many hours worth of videos are uploaded each second to YouTube. Recommending this recently uploaded (“fresh”) content is extremely important for YouTube as a product. We consistently observe that users prefer fresh content, though not at the expense of relevance.
Machine learning systems often exhibit an implicit bias towards the past because they are trained to predict future behavior from historical examples. To correct for this, we feed the age of the training example as a feature during training.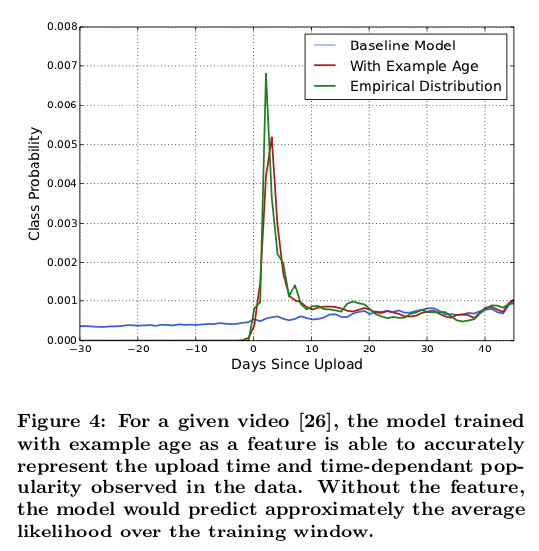
Label and Context Selection
王喆知乎
- 除了文中的单独对embedding层进行训练,还可以加上一个embedding层后跟DNN一起训练。优劣?
本文字字珠玑适合之后细读。
Airbnb
Real-time Personalization using Embeddings for Search Ranking at Airbnb
ABSTRACT
capture guest’s short-term and long-term interests, delivering effective home listing recommendations.
INTRODUCTION
Since guests typically conduct multiple searches before booking, i.e. click on more than one listing and contact more than one host during their search session, we can use these in-session signals, i.e. clicks, host contacts, etc. for Real-time Personalization where the aim is to show to the guest more of the listings similar to the ones we think they liked since staring the search session.
At the same time we can use the negative signal, e.g. skips of high ranked listings, to show to the guest less of the listings similar to the ones we think
they did not like .
use listing embeddings, low-dimensional vector representations learned from search sessions.
In addition to Real-time Personalization using immediate user actions, such as clicks, that can be used as proxy signal for short- term user interest, we introduce another type of embeddings trained on bookings to be able to capture user’s long-term interest.
Due to the nature of travel business, where users travel 1-2 times per year on average, bookings are a sparse signal, with a long tail of users with a single booking. To tackle this we propose to train embeddings at a level of user type, instead of a particular user id, where type is determined using many-to-one rule-based mapping that leverages known user attributes.
At the same time we learn listing type embeddings in the same vector space as user type embeddings. This enables us to calculate similarities between user type embedding of the user who is conducting a search and listing type embeddings of candidate listings that need to be ranked.
For short-term interest personalization they trained listing embeddings using more than 800 million search clicks sessions, resulting in high quality listing representations.
For long-term interest personalization we trained user type and listing type embeddings using sequences of booked listings by 50 million users. Both user and listing type embeddings were learned in the same vector space, such that we can calculate similarities between user type and listing types of listings that need to be ranked.
王喆知乎
具体到embedding上,文章通过两种方式生成了两种不同的embedding分别capture用户的short term和long term的兴趣。
- 一是通过click session数据生成listing的embedding,生成这个embedding的目的是为了进行listing的相似推荐,以及对用户进行session内的实时个性化推荐。
- 二是通过booking session生成user-type和listing-type的embedding,目的是捕捉不同user-type的long term喜好。由于booking signal过于稀疏,Airbnb对同属性的user和listing进行了聚合,形成了user-type和listing-type这两个embedding的对象。
第一个对listing进行embedding的方法:
Airbnb采用了click session数据对listing进行embedding,其中click session指的是一个用户在一次搜索过程中,点击的listing的序列,这个序列需要满足两个条件,一个是只有停留时间超过30s的listing page才被算作序列中的一个数据点,二是如果用户超过30分钟没有动作,那么这个序列会断掉,不再是一个序列。这么做的目的无可厚非,一是清洗噪声点和负反馈信号,二是避免非相关序列的产生。
有了由clicked listings组成的sequence,我们可以把这个sequence当作一个“句子”样本,开始embedding的过程。Airbnb不出意外的选择了word2vec的skip-gram model作为embedding方法的框架。通过修改word2vec的objective使其靠近Airbnb的业务目标。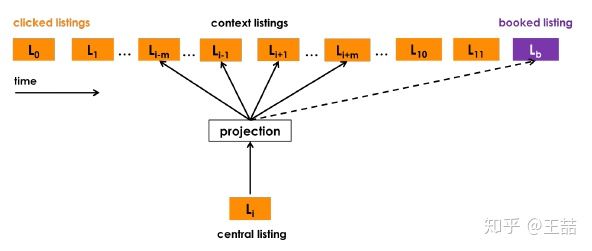
正样本很自然的取自click session sliding window里的两个listing,负样本则是在确定central listing后随机从语料库(这里就是listing的集合)中选取一个listing作为负样本。
因此,Airbnb初始的objective function几乎与word2vec的objective一模一样。
在原始word2vec embedding的基础上,针对其业务特点,Airbnb的工程师希望能够把booking的信息引入embedding。这样直观上可以使Airbnb的搜索列表和similar item列表中更倾向于推荐之前booking成功session中的listing。从这个motivation出发,Airbnb把click session分成两类,最终产生booking行为的叫booked session,没有的称做exploratory session。
文章多介绍了一下cold start的问题。简言之,如果有new listing缺失embedding vector,就找附近的3个同样类型、相似价格的listing embedding进行平均得到,不失为一个实用的工程经验。
embedding不仅encode了price,listing-type等信息,甚至连listing的风格信息都能抓住,说明即使我们不利用图片信息,也能从用户的click session中挖掘出相似风格的listing。
为了捕捉用户的长期偏好,airbnb在这里使用了booking session序列。比如用户j在过去1年依次book过5个listing。既然有了booking session的集合,我们是否可以像之前对待click session一样拿直接应用w2v的方法得到embedding呢?答案是否定的,因为我们会遇到非常棘手的数据稀疏问题。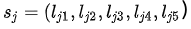
具体来讲booking session的数据稀疏问题表现在下面三点上:
- book行为的总体数量本身就远远小于click的行为,所以booking session集合的大小是远远小于click session的
- 单一用户的book行为很少,大量用户在过去一年甚至只book过一个房源,这导致很多booking session sequence的长度为1
- 大部分listing被book的次数也少的可怜,大家知道w2v要训练出较稳定有意义的embedding,item最少需要出现5-10次,但大量listing的book次数少于5次,根本无法得到有效的embedding。
Airbnb如何解决如此严重的数据稀疏问题,训练出有意义的user embedding和listing embedding呢?他们给出的答案是基于某些属性规则做相似user和相似listing的聚合。
可以之后再细读。