stacking技术分享
stacking不能称为一种算法,而是一种对模型的集成策略。在给定数据集的情况下,数据内部的空间结构和数据之间的关系是非常复杂得。不同的模型,其实很重要的一点就是在不同的角度去观测数据集。stacking框架就是用来取长补短进行结合的。
假设是五折的stacking,我们有一个train数据集和一个test数据集,那么一个基本的stacking框架会进行如下几个操作:
- 选择基模型。我们可以有xgboost,lightGBM,RandomForest,SVM,ANN,KNN,LR等等你能想到的各种基本算法模型。
- 把训练集分为不交叉的五份。我们标记为train1到train5。
- 从train1开始作为预测集,使用train2到train5建模,然后预测train1,并保留结果;然后,以train2作为预测集,使用train1,train3到train5建模,预测train2,并保留结果;如此进行下去,直到把train1到train5各预测一遍;
- 把预测的结果按照train1到trian5的位置对应填补上,得到对train整个数据集在第一个基模型的一个stacking转换。
- 在上述建立的五个模型过程中,每个模型分别对test数据集进行预测,并最终保留这五列结果,然后对这五列取平均,作为第一个基模型对test数据的一个stacking转换。
- 选择第二个基模型,重复以上2-5操作,再次得到train整个数据集在第二个基模型的一个stacking转换。
- 以此类推。有几个基模型,就会对整个train数据集生成几列新的特征表达。同样,也会对test有几列新的特征表达。
- 一般使用LR作为第二层的模型进行建模预测。
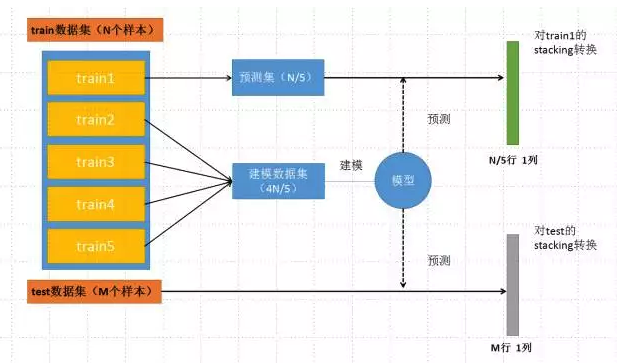
上面这个框架说明的是:对训练数据进行无重复的五次划分之后,分别对其中每一部分进行一次预测,而预测的模型就是由其余四部分训练的;并且在预测了预测集之后,还需要对我们的test数据集也进行一次预测,这这样就会得到5个N/5行、1列的对train数据集的特征转换,和5个M行、1列的对test数据集的特征转换,由此进入下一个图。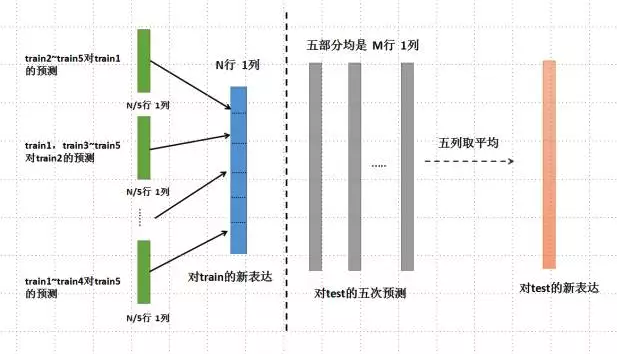
注意事项
1.stacking的框架设计比较复杂,对于一个基模型要训练5次,如果你的一个xgb模型要训练2个小时,即使在进行stacking的时候每折减少了五分之一的数据量,你的计算时间仍然是很可观的,加起来应该还是8-9小时,所以耗费时间很长(想像一下一个stacking框架跑一个基模型要大半天,简直太可怕)。所以建议大家在使用的时候要计算时间的耗费,或者可以改为3折,4折等等;
2、我们前面讲过了,stacking框架是集成了不同的算法,充分利用不同算法从不同的数据空间角度和数据结构角度的对数据的不同观测,来取长补短,优化结果。所以,我们的基模型除了是不同参数的相同模型之外,比如不同参数的xgboost,或者不同K值的KNN等等;更重要的是要尽可能的多加一些不同种类的基模型进去,也就是说所谓的模型要“跨越空间”的概念。这样的话我们的集成结果会更加稳健,更加精确。(曾经有一个比赛集成了上百个基模型的stacking框架获奖)
基本变种改进
在变种改进方面,我们可以不仅对模型进行融合,还可以对特征级进行一些变化,比如选部分特征做stacking;或者对stacking的结果进行再次的stacking,上面介绍的是两层的stacking,可以有3层,或者更多。但是时间复杂度很高,效果并不一定明显。
Kaggle数据挖掘比赛经验分享
【干货】Kaggle 数据挖掘比赛经验分享
一个完整的数据挖掘比赛基本流程如下:
数据分析
通过对数据进行探索性分析(甚至有些情况下需要肉眼观察样本),还可以有助于启发数据清洗和特征抽取,譬如缺失值和异常值的处理,文本数据是否需要进行拼写纠正等。
分析特征变量的分布
- 特征变量为连续值:如果为长尾分布并且考虑使用线性模型,可以对变量进行幂变换或者对数变换。
- 特征变量为离散值:观察每个离散值的频率分布,对于频次较低的特征,可以考虑统一编码为“其他”类别。
分析目标变量的分布
- 目标变量为连续值:查看其值域范围是否较大,如果较大,可以考虑对其进行对数变换,并以变换后的值作为新的目标变量进行建模(在这种情况下,需要对预测结果进行逆变换)。一般情况下,可以对连续变量进行Box-Cox变换。通过变换可以使得模型更好的优化,通常也会带来效果上的提升。
- 目标变量为离散值:如果数据分布不平衡,考虑是否需要上采样/下采样;如果目标变量在某个ID上面分布不平衡,在划分本地训练集和验证集的时候,需要考虑分层采样(Stratified Sampling)。
分析变量之间两两的分布和相关度
- 可以用于发现高相关和共线性的特征。
数据清洗
数据清洗是指对提供的原始数据进行一定的加工,使得其方便后续的特征抽取。其与特征抽取的界限有时也没有那么明确。常用的数据清洗一般包括:
数据的拼接
- 提供的数据散落在多个文件,需要根据相应的键值进行数据的拼接。
特征缺失值的处理
- 特征值为连续值:按不同的分布类型对缺失值进行补全:偏正态分布,使用均值代替,可以保持数据的均值;偏长尾分布,使用中值代替,避免受 outlier 的影响;
- 特征值为离散值:使用众数代替。
文本数据的清洗
- 在比赛当中,如果数据包含文本,往往需要进行大量的数据清洗工作。如去除HTML 标签,分词,拼写纠正, 同义词替换,去除停词,抽词干,数字和单位格式统一等。
特征工程
有一种说法是,特征决定了效果的上限,而不同模型只是以不同的方式或不同的程度来逼近这个上限。这样来看,好的特征输入对于模型的效果至关重要,正所谓”Garbage in, garbage out”。要做好特征工程,往往跟领域知识和对问题的理解程度有很大的关系,也跟一个人的经验相关。特征工程的做法也是Case by Case,以下就一些点,谈谈自己的一些看法。
特征变换
主要针对一些长尾分布的特征,需要进行幂变换或者对数变换,使得模型(LR或者DNN)能更好的优化。需要注意的是,Random Forest 和 GBDT 等模型对单调的函数变换不敏感。其原因在于树模型在求解分裂点的时候,只考虑排序分位点。
特征编码
对于离散的类别特征,往往需要进行必要的特征转换/编码才能将其作为特征输入到模型中。常用的编码方式有 LabelEncoder,OneHotEncoder(sklearn里面的接口)。譬如对于”性别”这个特征(取值为男性和女性),使用这两种方式可以分别编码为{0,1}和{[1,0], [0,1]}。
对于取值较多(如几十万)的类别特征(ID特征),直接进行OneHotEncoder编码会导致特征矩阵非常巨大,影响模型效果。可以使用如下的方式进行处理:
◆ 统计每个取值在样本中出现的频率,取 Top N 的取值进行 One-hot 编码,剩下的类别分到“其他“类目下,其中 N 需要根据模型效果进行调优;
◆ 统计每个 ID 特征的一些统计量(譬如历史平均点击率,历史平均浏览率)等代替该 ID 取值作为特征,具体可以参考 Avazu 点击率预估比赛第二名的获奖方案;
◆ 参考 word2vec 的方式,将每个类别特征的取值映射到一个连续的向量,对这个向量进行初始化,跟模型一起训练。训练结束后,可以同时得到每个ID的Embedding。具体的使用方式,可以参考 Rossmann 销量预估竞赛第三名的获奖方案,https://github.com/entron/entity-embedding-rossmann。
对于 Random Forest 和 GBDT 等模型,如果类别特征存在较多的取值,可以直接使用 LabelEncoder 后的结果作为特征(这里应该只是将数字来代替类别,数字并不具有实际含义)。注意labelEncoder将文字变换为数字,是虚拟数据,不一定有意义,建模时要注意去除。
模型训练和验证
模型选择
在处理好特征后,我们可以进行模型的训练和验证。
◆ 对于稀疏型特征(如文本特征,One-hot的ID类特征),我们一般使用线性模型,譬如 Linear Regression 或者 Logistic Regression。Random Forest 和 GBDT 等树模型不太适用于稀疏的特征,但可以先对特征进行降维(如PCA,SVD/LSA等),再使用这些特征。稀疏特征直接输入 DNN 会导致网络 weight 较多,不利于优化,也可以考虑先降维,或者对 ID 类特征使用 Embedding 的方式;
◆ 对于稠密型特征,推荐使用 XGBoost 进行建模,简单易用效果好;
◆ 数据中既有稀疏特征,又有稠密特征,可以考虑使用线性模型对稀疏特征进行建模,将其输出与稠密特征一起再输入 XGBoost/DNN 建模,具体可以参考Stacking 部分。
调参和模型验证
对于选定的特征和模型,我们往往还需要对模型进行超参数的调优,才能获得比较理想的效果。调参一般可以概括为以下三个步骤:
1.训练集和验证集的划分。根据比赛提供的训练集和测试集,模拟其划分方式对训练集进行划分为本地训练集和本地验证集。划分的方式视具体比赛和数据而定,常用的方式有:
a) 随机划分:譬如随机采样 70% 作为训练集,剩余的 30% 作为测试集。在这种情况下,本地可以采用 KFold 或者 Stratified KFold 的方法来构造训练集和验证集。
b) 按时间划分:一般对应于时序序列数据,譬如取前 7 天数据作为训练集,后 1 天数据作为测试集。这种情况下,划分本地训练集和验证集也需要按时间先后划分。常见的错误方式是随机划分,这种划分方式可能会导致模型效果被高估。
c) 按某些规则划分:在 HomeDepot 搜索相关性比赛中,训练集和测试集中的 Query 集合并非完全重合,两者只有部分交集。而在另外一个相似的比赛中(CrowdFlower 搜索相关性比赛),训练集和测试集具有完全一致的 Query 集合。对于 HomeDepot 这个比赛中,训练集和验证集数据的划分,需要考虑 Query 集合并非完全重合这个情况,其中的一种方法可以参考第三名的获奖方案,https://github.com/ChenglongChen/Kaggle_HomeDepot。
2.指定参数空间。在指定参数空间的时候,需要对模型参数以及其如何影响模型的效果有一定的了解,才能指定出合理的参数空间。譬如DNN或者XGBoost中学习率这个参数,一般就选 0.01 左右就 OK 了(太大可能会导致优化算法错过最优化点,太小导致优化收敛过慢)。再如 Random Forest,一般设定树的棵数范围为 100~200 就能有不错的效果,当然也有人固定数棵数为 500,然后只调整其他的超参数。
3.按照一定的方法进行参数搜索。常用的参数搜索方法有,Grid Search,Random Search以及一些自动化的方法(如 Hyperopt)。其中,Hyperopt 的方法,根据历史已经评估过的参数组合的效果,来推测本次评估使用哪个参数组合更有可能获得更好的效果。
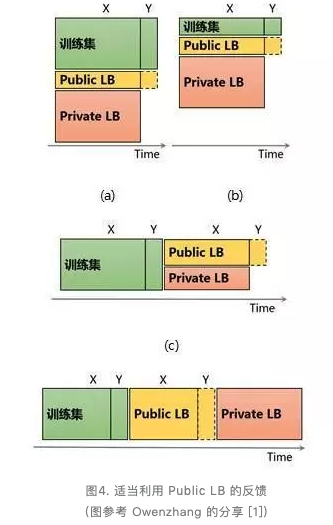
适当利用 Public LB 的反馈
模型集成
Averaging 和 Voting
直接对多个模型的预测结果求平均或者投票。对于目标变量为连续值的任务,使用平均;对于目标变量为离散值的任务,使用投票的方式。
Stacking
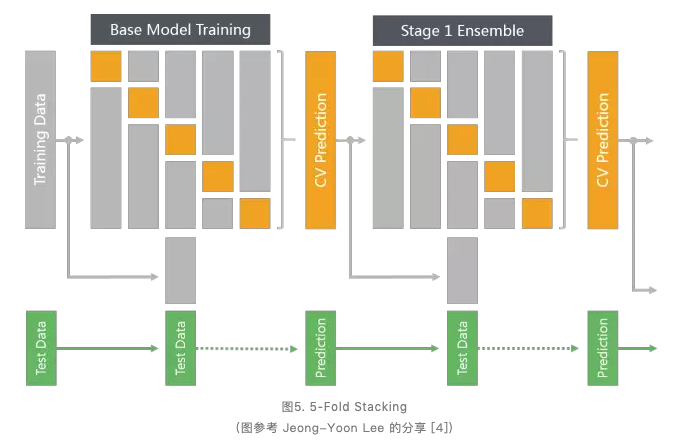
- 数据集划分。将训练数据按照5-Fold进行划分(如果数据跟时间有关,需要按时间划分)
- 基础模型训练 I。按照交叉验证(Cross Validation)的方法,在训练集(Training Fold)上面训练模型(如图灰色部分所示),并在验证集(Validation Fold)上面做预测,得到预测结果(如图黄色部分所示)。最后综合得到整个训练集上面的预测结果(如图第一个黄色部分的CV Prediction所示)。
- 基础模型训练 II(如图5第二和三行左半部分所示)。在全量的训练集上训练模型(如图第二行灰色部分所示),并在测试集上面做预测,得到预测结果(如图第三行虚线后绿色部分所示)。
- Stage 1 模型集成训练 I(如图5第一行右半部分所示)。将步骤 2 中得到的 CV Prediction 当作新的训练集,按照步骤 2 可以得到 Stage 1模型集成的 CV Prediction。
- Stage 1 模型集成训练 II(如图5第二和三行右半部分所示)。将步骤 2 中得到的 CV Prediction 当作新的训练集和步骤 3 中得到的 Prediction 当作新的测试集,按照步骤 3 可以得到 Stage 1 模型集成的测试集 Prediction。此为 Stage 1 的输出,可以提交至 Kaggle 验证其效果。
在图5中,基础模型只展示了一个,而实际应用中,基础模型可以多种多样,如SVM,DNN,XGBoost 等。也可以相同的模型,不同的参数,或者不同的样本权重。重复4和5两个步骤,可以相继叠加 Stage 2, Stage 3 等模型。
Blending
Blending 与 Stacking 类似,但单独留出一部分数据(如 20%)用于训练 Stage X 模型。
Bagging Ensemble Selection
Bagging Ensemble Selection [5] 是我在 CrowdFlower 搜索相关性比赛中使用的方法,其主要的优点在于可以以优化任意的指标来进行模型集成。这些指标可以是可导的(如 LogLoss 等)和不可导的(如正确率,AUC,Quadratic Weighted Kappa等)。它是一个前向贪婪算法,存在过拟合的可能性,作者在文献 [5] 中提出了一系列的方法(如 Bagging)来降低这种风险,稳定集成模型的性能。使用这个方法,需要有成百上千的基础模型。为此,在 CrowdFlower 的比赛中,我把在调参过程中所有的中间模型以及相应的预测结果保留下来,作为基础模型。这样做的好处是,不仅仅能够找到最优的单模型(Best Single Model),而且所有的中间模型还可以参与模型集成,进一步提升效果。
自动化框架
这份代码开源在 Github 上面,目前是 Github 有关 Kaggle 竞赛解决方案的 Most Stars,地址:https://github.com/ChenglongChen/Kaggle_CrowdFlower。
其主要包含以下部分:
1.模块化特征工程
a) 接口统一,只需写少量的代码就能够生成新的特征;
b) 自动将单独的特征拼接成特征矩阵。
2.自动化模型调参和验证
a) 自定义训练集和验证集的划分方法;
b) 使用 Grid Search / Hyperopt 等方法,对特定的模型在指定的参数空间进行调优,并记录最佳的模型参数以及相应的性能。
3.自动化模型集成
a) 对于指定的基础模型,按照一定的方法(如Averaging_Stacking_Blending 等)生成集成模型。