Kaggle_CrowdFlower
GitHub - ChenglongChen/Kaggle_CrowdFlower: 1st Place Solution for Search Results Relevance Competition on Kaggle (https://www.kaggle.com/c/crowdflower-search-relevance)
1st Place Solution for Search Results Relevance Competition on Kaggle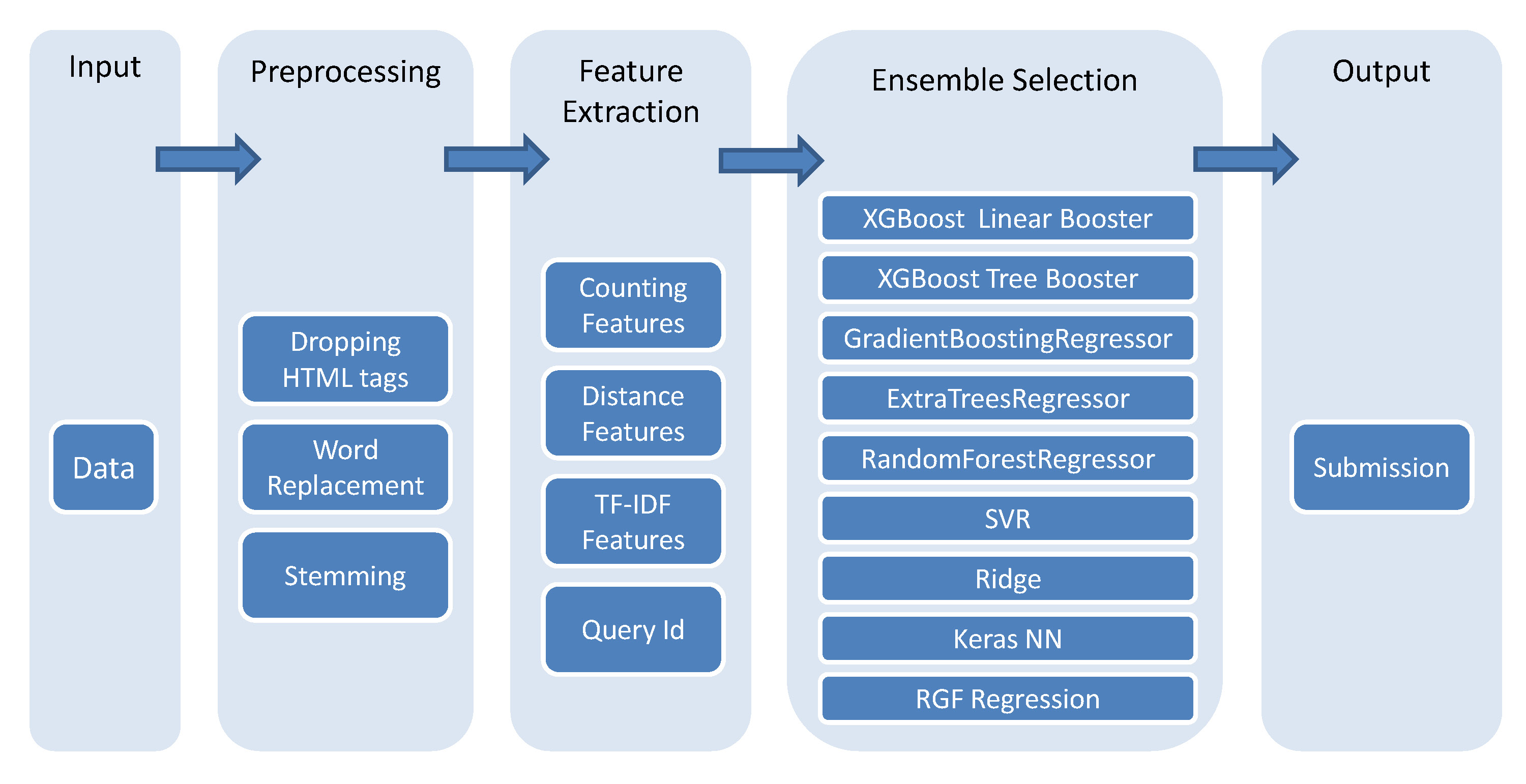
问题描述:搜索结果相关挑战,给定搜索结果,搜索出的产品名称,产品描述,建立模型去预测搜索结果的相关得分。
概述
解决方案分为两部分:特征工程和模型集成。
特征包括三部分的特征:
1.计数特征
2.距离特征
3.TF-IDF特征
在生产特征前,对数据进行拼写检查,同义词替换,词干提取是非常有用的。模型集成包括两个主要的步骤,首先,使用不同种,不同参数设置,不同特征子集去训练模型。然后使用训练的模型进行bagged集成选择。在训练集上使用交叉验证来评估表现。
预处理
进行了几步去清洗文本。
去除HTML标签
在商品描述中存在html标签的干扰,使用bs4去除之。
单词替换
在搜索中会出现词义相关的搜索,要考虑到。
1.拼写纠正
2.同义词替换
3.词干提取
特征提取/选择
$$\left(q_{i}, t_{i}, d_{i}\right)$$是train.csv以及test.csv中的第i个样本,qi是查询,ti是产品名,di是产品描述。使用ri和vi来表示median_relevance和relevance_variance。使用函数ngram(s,n)去提取句子中的n个词。例如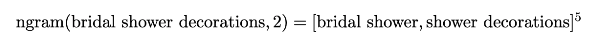
计数特征
为$$\left{q_{i}, t_{i}, d_{i}\right}$$生成计数特征。
基础计数特征

交叉计数特征
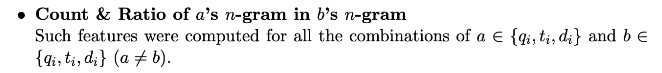
交叉位置特征

距离特征
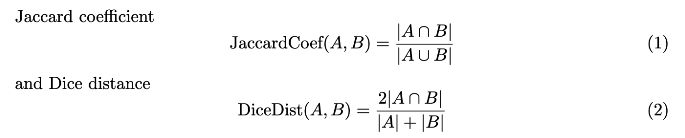
TF-IDF特征
其他特征
查询ID
将查询id进行独热编码。
特征选择
相同的模型经常被用来在特征集上进行交叉验证来测试与之前的特征集合相比是否得分有所提升。对于高维特征,使用XGBoost with linear booster(MSE为目标函数),对于低维特征使用sklearn中的ExtraTreesRegressor。
值得注意的是,有了集成选择(ensemble selection),我们可以利用不同的特征集合来训练特征库,并且利用集成选择去挑选出最佳的集成。但是特征选择依旧有用。使用上述的特征选择,可以首先明确一些表现好的特征集合,然后使用其去训练模型,这会在一定程度上减少计算负担。
模型技术和训练
交叉验证方法学
划分
StratifiedKFold
Kaggle_HomeDepot
Kaggle——销售量预测
比赛地址Predict Future Sales | Kaggle
这个比赛作为经典的时间序列问题之一,目标是为了预测下个月每种产品和商店的总销售额。
以下为1st solution。
part1 hands on data
https://www.kaggle.com/kyakovlev/1st-place-solution-part-1-hands-on-data/notebook
数据域含义

数据集情况: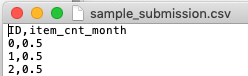
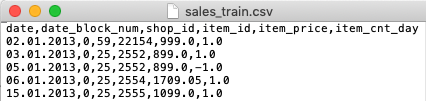
trick1
downcasting DataFrame. It will save some memory, everyone will need all memory possible.
In this case from 134.4MB to 61.6 MB
trick2
pd.pivot_table()透视表功能
trick3
利用图像去除极端值
使用seaborn。boxplot
item_id
以item_id为索引,月份为列名生成表格来观察数据。
分析每个月销售的总和的趋势。
分析每个平均一个商品销售的趋势(和👆趋势一致)
查看有多少6个月来没有销售记录的商品
查看测试数据中有多少这样过期的商品
查看价格和销售额的离群点
可能的特征:
- 时间间隔
- 商品放出的日期
- 上月的销售
- 销售的日期
- 临近的商品(id1000与1001的商品可能有所相似)
shop_id
以shop_id为索引,月份为列名生成表格来观察数据。
查看最近开张的商店数
查看最近倒闭的商店数
可能的特征:
- 时间间隔(shop_id/shp_cnt_mth)
- 开业月份(可能的开业促销活动)
- 倒闭月份(可能的清仓大甩卖)
price
可能的特征: - 价格分档(1/10/20/等等),显然,更低价的物品拥有着更大的销量。
- 打折和打折期间
- 价格的时间间隔(显示打折)
- 价格修正
- 店铺的收入
dates
可能的日期特征: - 周末和假期的销售额(去修正月度的销售)
- 该月有几天(去修正月度的销售)
- 是第几个月(与季节性的物品有关)
shop info
shop city | shop type | shop name
可能的商店特征:
- shop city
- shop type
items.csv
从items.csv中挖掘特征
可能的特征,1.item name 2.Encoded aditional feature
category.csv
category.csv中满足的格式
可能的种类特征:
- 部分
- 主要种类的名字
- 主要子种类的名字
- 第二子种类的名字
test set
对测试数据集进行分析
将测试条目分为三组:
- Item/shop pairs that are in train
- Items without any data
- Items that are in train
Kaggle——销售量预测
没有看错,接下来是另一个solution
主要是Feature Engineering,XGBoost
https://www.kaggle.com/dlarionov/feature-engineering-xgboost
part1 ,perfect features
同样使用sns 显示后,去除离群点
其中有一个物品的价格是负,使用价格中位数来替换之。
根据名字来看有些商店id重复出现了,fix it。
对于商店,种类,物品进行预处理
Monthly sales
新增特征revenue:
train[‘revenue’] = train[‘item_price’] * train[‘item_cnt_day’]
测试集是34个月中一些商店和一些物品的组合,共有5100 items * 42 shops = 2142400对组合。363个物品在训练集中是没有的。因此,对于大多数测试集中的物品目标值应该是0.另一个方面,训练集只包含过去售出或者退回的对。主要的思路是计算月度的销售将其在当月的对中用0值进行扩展。这样训练数据将会与测试数据相似。
将训练集中的 shop/item对去聚合去计算目标聚合,然后将目标值截取为(0,20),这样训练目标值将会与测试预测相似。
测试集
将测试集的月份设置为34,并与训练集进行合并
Shops/Items/Cats features
将shop,item,item_category表进行合并
Traget lags
相当于将窗口移动,[0,33],lags为1则为[1,33]
均值编码特征
表格的特征的命名形式为 feature1_feature2_avg_feature_cnt
意思为选定feature1,feature2,来聚合feature_cnt求均值。
求每个月中物品售出的均值数 0.3左右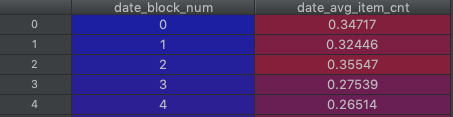
求每个月中每个物品所对应的均值(可以理解为平均每家商店售出的值)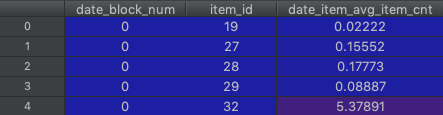
选定date_block_num,shop_id,在item_cnt_month聚合求均值
可以理解为一个月一家店销售物品数量的均值数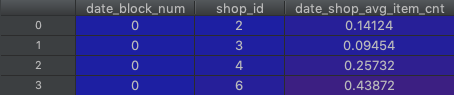
同理还有:
选定date_block_num,item_category_id,在item_cnt_month聚合求均值
选定date_block_num,item_category_id,shop_id,在item_cnt_month聚合求均值
选定date_block_num,type_code,shop_id,在item_cnt_month聚合求均值
选定date_block_num,subtype_code,shop_id,在item_cnt_month聚合求均值
选定date_block_num,city_code,在item_cnt_month聚合求均值
选定date_block_num,city_code,item_id 在item_cnt_month聚合求均值
选定date_block_num,type_code 在item_cnt_month聚合求均值
选定date_block_num,subtype_code 在item_cnt_month聚合求均值
trend features
上六个月的价格趋势。
上个月的商店的营收趋势。
Special features
将月份中添加上天数
对于每个shop/item对上一笔销售的月,使用编程方法实现:
创建HashTable键值等于{shop_id,item_id},值等于date_block_num。对于数据表从上往下迭代。如果{row.shop_id,row.item_id}不在表中,则添加进表中,并将值设为row.date_block_num。如果HashTable中包含值,则计算cached value与row.date_block_num。
Months since the first sale for each shop/item pair and for item only.
最终准备
Because of the using 12 as lag value drop first 12 months. Also drop all the columns with this month calculated values (other words which can not be calcucated for the test set).
Producing lags brings a lot of nulls.