莫凡 使用Numpy的技巧
pandas要比Numpy慢,所以尽量避免使用Pandas。
为什么用Numpy?
Python 是慢的, 简单来说, 因为 Python 执行代码的时候会执行很多复杂的“check” 功能, 比如赋值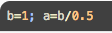
在计算机内部, b 首先要从一个整数 integer 转换成浮点数 float, 才能进行后面的 b/0.5, 因为得到的要是一个小数.提到 Numpy, 它就是一个 Python 的救星. 能把简单好用的 Python 和高性能的 C 语言合并在一起. 当你调用 Numpy 功能的时候, 他其实调用了很多 C 语言而不是纯 Python. 这就是为什么大家都爱用 Numpy 的原因.
创建Numpy Array的结构
其实 Numpy 就是 C 的逻辑, 创建存储容器 “Array” 的时候是寻找内存上的一连串区域来存放, 而 Python 存放的时候则是不连续的区域, 这使得 Python 在索引这个容器里的数据时不是那么有效率. Numpy 只需要再这块固定的连续区域前后走走就能不费吹灰之力拿到数据.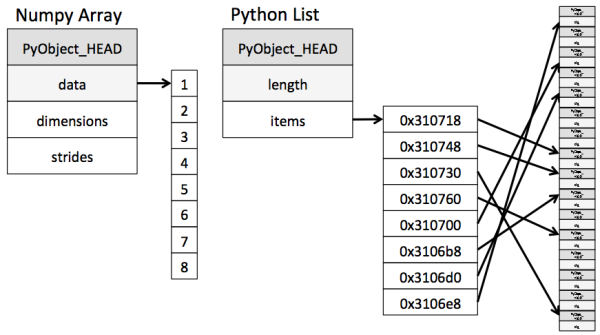
在运用 Numpy 的时候, 我们通常不是用一个一维 Array 来存放数据, 而是用二维或者三维的块来存放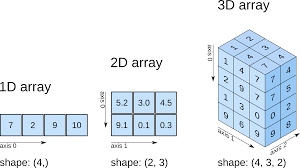
因为 Numpy 快速的矩阵相乘运算, 能将乘法运算分配到计算机中的多个核, 让运算并行. 这种并行运算大大加速了运算速度.
不管是1D,2D,3D 的 Array, 从根本上, 它都是一个 1D array。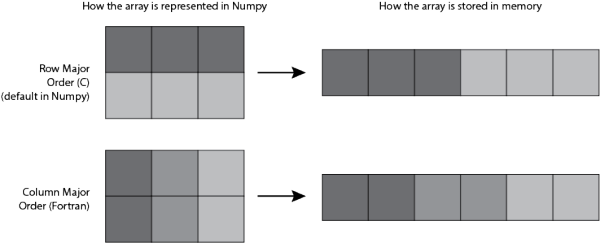
2D Array, 如果追溯到计算机内存里, 它其实是储存在一个连续空间上的. 而对于这个连续空间, 我们如果创建 Array 的方式不同, 在这个连续空间上的排列顺序也有不同. 这将影响之后所有的事情!
在 Numpy 中, 创建 2D Array 的默认方式是 “C-type” 以 row 为主在内存中排列, 而如果是 “Fortran” 的方式创建的, 就是以 column 为主在内存中排列.
在 Axis 上的动作
当你的计算中涉及合并矩阵, 不同形式的矩阵创建方式会有不同的时间效果. 因为在 Numpy 中的矩阵合并等, 都是发生在一维空间里 ! 不是二维空间中!
从上面的那张图, 可以想到, row 为主的存储方式, 如果在 row 的方向上合并矩阵, 将会更快. 因为只要我们将思维放在 1D array 那, 直接再加一个 row 放在1D array 后面就好了。
但是在以 column 为主的系统中, 往 1D array 后面加 row 的规则变复杂了, 消耗的时间也变长. 如果以 axis=1 的方式合并, “F” 方式将会比 “C” 方式更好.
在数组的拼接中,对比np.stack和np.concatenate,通过测试发现,为了速度,尽量使用np.concatenate。
copy慢,view快
在 Numpy 中, 有两个很重要的概念, copy 和 view. copy 顾名思义, 会将数据 copy 出来存放在内存中另一个地方, 而 view 则是不 copy 数据, 直接取源数据的索引部分.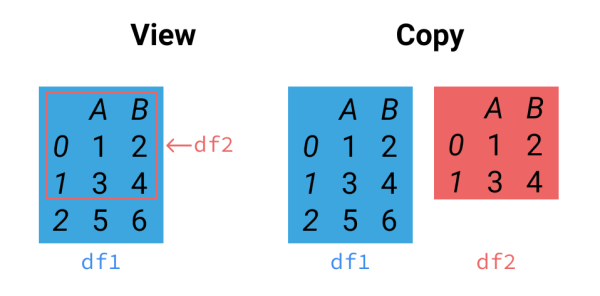
简单说, a_view 的东西全部都是 a 的东西, 动 a_view 的任何地方, a 都会被动到, 因为他们在内存中的位置是一模一样的, 本质上就是自己. 而 a_copy 则是将 a copy 了一份, 然后把 a_copy 放在内存中的另外的地方, 这样改变 a_copy, a 是不会被改变的.
因为 view 不会复制东西, 速度快。
对于 view 还有一点要提,把一个矩阵展平, 用到 np.flatten() 或者np.ravel(). 他俩是不同的!ravel 返回的是一个 view (官方说如果用 ravel, 需要 copy 的时候才会被 copy , 我想这个时候可能是把 ravel 里面 order 转换的时候, 如 ‘C-type’ -> ‘Fortran’), 而 flatten 返回的总是一个 copy. 相比于 flatten, ravel 是神速.
选择数据
选择数据的时候, 我们常会用到 view 或者 copy 的形式. 我们知道了, 如果能用到 view 的, 我们就尽量用 view, 避免 copy 数据.下面举例的都是 view 的方式: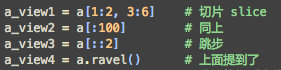
使用copy的方式:
对于fancy indexing的形式,我们也是可以对它加速。
1.使用np.take(), 替代用 index 选数据的方法.
像 a_copy1 = a[ [1,4,6] , [2,4,6] ], 用 take 在大部分情况中会比这样的 a_copy1 要快.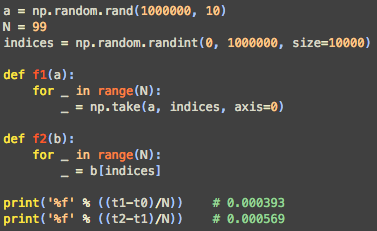
2 使用 np.compress(), 替代用 mask 选数据的方法.
a_copy2 = a[ [ True, True] , [ False, True]] 这种就是用 TRUE, FALSE 来选择数据的.
非常有用的out参数
下面两个其实在功能上是没差的, 不过运算时间上有差, 我觉得可能是 a=a+1 要先转换成 np.add() 这种形式再运算, 所以前者要用更久一点的时间.
这两个被赋值的 a, 都是原来 a 的一个 copy, 并不是 a 的 view. 但是在功能里面有一个 out 参数, 让我们不必要重新创建一个 a. 所以下面两个是一样的功能, 都不会创建另一个 copy. 可能是上面提到的那个原因, 这里的运算时间也有差.
所以只要是已经存在了一个 placeholder (比如 a), 我们就没有必要去再创建一个, 用 out 方便又有效.
给数据一个名字
使用Numpy的structured array.
pandas 为什么比 numpy 慢, 因为 pandas data 里面还有很多七七八八的数据, 记录着这个 data 的种种其他的特征.