让爬虫程序更像人类用户的行为
Python3网络爬虫(十一):爬虫黑科技之让你的爬虫程序更像人类用户的行为(代理IP池等) - Jack-Cui - CSDN博客
黑科技
一些简单的方法让爬虫更像人类访问用户。
构造合理的HTTP请求头
设置Cookie的学问
虽然 cookie 是一把双刃剑,但正确地处理 cookie 可以避免许多采集问题。网站会用 cookie 跟踪你的访问过程,如果发现了爬虫异常行为就会中断你的访问,比如特别快速地填写表单,或者浏览大量页面。虽然这些行为可以通过关闭并重新连接或者改变 IP 地址来伪装,但是如果 cookie 暴露了你的身份,再多努力也是白费。
在采集一些网站时 cookie 是不可或缺的。要在一个网站上持续保持登录状态,需要在多个页面中保存一个 cookie。有些网站不要求在每次登录时都获得一个新 cookie,只要保存一个旧的“已登录”的 cookie 就可以访问。
Cookie信息,也可以更具实际情况填写。不过requests已经封装好了很多操作,自动管理cookie,session保持连接。我们可以先访问某个目标网站,建立一个session连接之后,获取cookie。代码如下:
使用 requests.Session 会话对象让你能够跨请求保持某些参数,它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能。
因为 requests 模块不能执行 JavaScript,所以它不能处理很多新式的跟踪软件生成的 cookie,比如 Google Analytics,只有当客户端脚本执行后才设置 cookie(或者在用户浏览页面时基于网页事件产生 cookie,比如点击按钮)。要处理这些动作,需要用 Selenium 和 PhantomJS 包。
PhantomJS 是一个“无头”(headless)浏览器。它会把网站加载到内存并执行页面上的 JavaScript,但不会向用户展示网页的图形界面。将 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,可以处理 cookie、JavaScript、headers,以及任何你需要做的事情。
还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。另外,还可以保存 cookie 以备其他网络爬虫使用。
通过Selenium和PhantomJS,我们可以很好的处理一些需要事件执行后才能获得的cookie。
正常的访问速度
有一些防护措施完备的网站可能会阻止你快速地提交表单,或者快速地与网站进行交互。即使没有这些安全措施,用一个比普通人快很多的速度从一个网站下载大量信息也可能让自己被网站封杀。
因此,虽然多进程程序可能是一个快速加载页面的好办法——在一个进程中处理数据,另一个进程中加载页面——但是这对编写好的爬虫来说是恐怖的策略。还是应该尽量保证一次加载页面加载且数据请求最小化。如果条件允许,尽量为每个页面访问增加一点儿时间间隔,即使你要增加两行代码:
合理控制速度是你不应该破坏的规则。过度消耗别人的服务器资源会让你置身于非法境地,更严重的是这么做可能会把一个小型网站拖垮甚至下线。拖垮网站是不道德的,是彻头彻尾的错误。所以请控制采集速度!
注意隐含输入字段
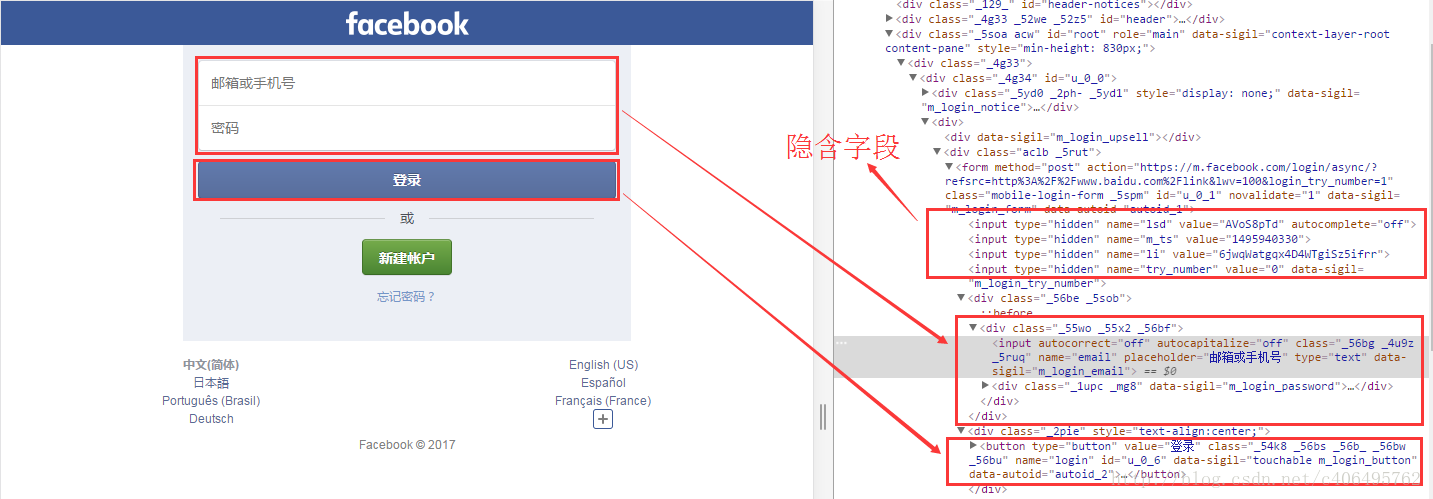
用隐含字段阻止网络数据采集的方式主要有两种。
第一种是表单页面上的一个字段可以用服务器生成的随机变量表示。如果提交时这个值不在表单处理页面上,服务器就有理由认为这个提交不是从原始表单页面上提交的,而是由一个网络机器人直接提交到表单处理页面的。绕开这个问题的最佳方法就是,首先采集表单所在页面上生成的随机变量,然后再提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单里包含一个具有普通名称的隐含字段(设置蜜罐圈套),比如“用户名”(username)或“邮箱地址”(email address),设计不太好的网络机器人往往不管这个字段是不是对用户可见,直接填写这个字段并向服务器提交,这样就会中服务器的蜜罐圈套。服务器会把所有隐含字段的真实值(或者与表单提交页面的默认值不同的值)都忽略,而且填写隐含字段的访问用户也可能被网站封杀。
总之,有时检查表单所在的页面十分必要,看看有没有遗漏或弄错一些服务器预先设定好的隐含字段(蜜罐圈套)。如果你看到一些隐含字段,通常带有较大的随机字符串变量,那么很可能网络服务器会在表单提交的时候检查它们。另外,还有其他一些检查,用来保证这些当前生成的表单变量只被使用一次或是最近生成的(这样可以避免变量被简单地存储到一个程序中反复使用)。
爬虫如何避开蜜罐
虽然在进行网络数据采集时用 CSS 属性区分有用信息和无用信息会很容易(比如,通过读取 id和 class 标签获取信息),但这么做有时也会出问题。如果网络表单的一个字段通过 CSS 设置成对用户不可见,那么可以认为普通用户访问网站的时候不能填写这个字段,因为它没有显示在浏览器上。如果这个字段被填写了,就可能是机器人干的,因此这个提交会失效。
这种手段不仅可以应用在网站的表单上,还可以应用在链接、图片、文件,以及一些可以被机器人读取,但普通用户在浏览器上却看不到的任何内容上面。访问者如果访问了网站上的一个“隐含”内容,就会触发服务器脚本封杀这个用户的 IP 地址,把这个用户踢出网站,或者采取其他措施禁止这个用户接入网站。实际上,许多商业模式就是在干这些事情。
通常元素可以通过三种不同的方式对用户进行隐藏。
- 第一个链接是通过简单的 CSS 属性设置 display:none 进行隐藏;
- 电话号码字段 name=”phone” 是一个隐含的输入字段;
- 邮箱地址字段 name=”email” 是将元素向右移动 50 000 像素(应该会超出电脑显示器的边界)并隐藏滚动条。
因为 Selenium 可以获取访问页面的内容,所以它可以区分页面上的可见元素与隐含元素。通过 is_displayed() 可以判断元素在页面上是否可见。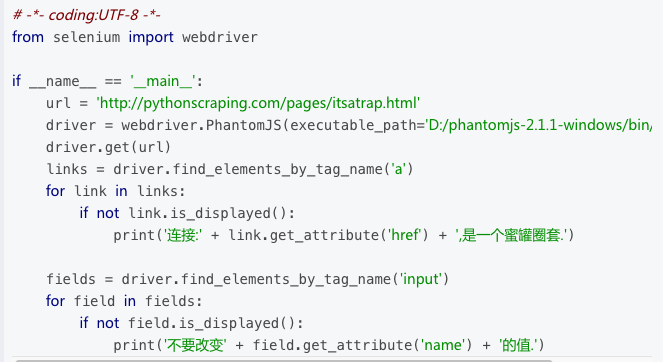
创建自己的代理IP池
启用远程平台的人通常有两个目的:对更大计算能力和灵活性的需求,以及对可变 IP 地址的需求。
有一些网站会设置访问阈值,也就是说,如果一个IP访问速度超过这个阈值,那么网站就会认为,这是一个爬虫程序,而不是用户行为。为了避免远程服务器封锁IP,或者想加快爬取速度,一个可行的方法就是使用代理IP,我们需要做的就是创建一个自己的代理IP池。
思路:通过免费IP代理网站爬取IP,构建一个容量为100的代理IP池。从代理IP池中随机选取IP,在使用IP之前,检查IP是否可用。如果可用,使用该IP访问目标页面,如果不可用,舍弃该IP。当代理IP池中IP的数量小于20的时候,更新整个代理IP池,即重新从免费IP代理网站爬取IP,构建一个新的容量为100的代理IP池。
检查列表
如果一直被网站封杀找不到原因,可以从以下方面来检查。
检查 JavaScript
如果你从网络服务器收到的页面是空白的,缺少信息,或其遇到他不符合你预期的情况(或者不是你在浏览器上看到的内容),有可能是因为网站创建页面的 JavaScript 执行有问题。
检查正常浏览器提交的参数
如果你准备向网站提交表单或发出 POST 请求,记得检查一下页面的内容,看看你想提交的每个字段是不是都已经填好,而且格式也正确。用 Chrome 浏览器的网络面板(快捷键 F12 打开开发者控制台,然后点击“Network”即可看到)查看发送到网站的 POST 命令,确认你的每个参数都是正确的。
是否有合法的 Cookie?
如果你已经登录网站却不能保持登录状态,或者网站上出现了其他的“登录状态”异常,请检查你的 cookie。确认在加载每个页面时 cookie 都被正确调用,而且你的 cookie 在每次发起请求时都发送到了网站上。
IP 被封禁
如果你在客户端遇到了 HTTP 错误,尤其是 403 禁止访问错误,这可能说明网站已经把你的 IP 当作机器人了,不再接受你的任何请求。你要么等待你的 IP 地址从网站黑名单里移除,要么就换个 IP 地址。如果你确定自己并没有被封杀,那么再检查下面的内容:
- 确认你的爬虫在网站上的速度不是特别快。快速采集是一种恶习,会对网管的服务器造成沉重的负担,还会让你陷入违法境地,也是 IP 被网站列入黑名单的首要原因。给你的爬虫增加延迟,让它们在夜深人静的时候运行。切记:匆匆忙忙写程序或收集数据都是拙劣项目管理的表现;应该提前做好计划,避免临阵慌乱。
- 还有一件必须做的事情:修改你的请求头!有些网站会封杀任何声称自己是爬虫的访问者。如果你不确定请求头的值怎样才算合适,就用你自己浏览器的请求头吧。
- 确认你没有点击或访问任何人类用户通常不能点击或接入的信息。
- 如果你用了一大堆复杂的手段才接入网站,考虑联系一下网管吧,告诉他们你的目的。试试发邮件到 webmaster@< 域名 > 或 admin@< 域名 >,请求网管允许你使用爬虫采集数据。管理员也是人嘛!
使用免费的代理IP也是有局限的,就是不稳定。更好的方法是,花钱买一个可以动态切换IP的阿里云服务器,这样IP就可以无限动态变化了!