数据分析小总结
数据挖掘的十大算法
分类算法
C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN,Adaboost,CART
聚类算法
K-Means,EM
关连分析
Apriori
[‘eɪprɪ’ɔ:rɪ] 先验的
Aprion是一种挖掘关联规则( association rules)的算法,它通过挖掘频繁项集( frequent item sets)来揭示物品之间的关联关系,被广泛应用到商业挖掘和网络安全等领域中。频繁项集是指经常岀现在一起的物品的集合,关联规则暗示着两种物品之间可能存在很强的关系。
连接分析
PageRank
PageRank起源于论文影响力的计算方式,如果一篇文论被引入的次数越多,就代表这篇论文的影响力越强。同样 PageRank被 Google创造性地应用到了网页权重的计算中:当一个页面链岀的页面越多,说明这个页面的“参考文献”越多,当这个页面被链入的频率越高,说明这个页面被引用的次数越高。基于这个原理,我们可以得到网站的权重划分。
Numpy之再回首
使用NumPy让Python科学计算更高效
列表list的元素在系统内存中是分散存储的,而 NumPy数组存储在一个均匀连续的内存块中。这样数组计算遍历所有的元素,不像列表list还需要对內存地址进行査找,从而节省了计算资源。由之前的NumPy博客可得知详情。
Python数据科学手册 NumPy入门 | ZDK’s blog
然而一旦确定下来numpy数组后,就不能在增加元素了。
另外在内存访问模式中,缓存会直接把字节块从RAM加载到CPU寄存器中。因为数据连续的存储在内存中, NumPy直接利用现代CPU的矢量化指令计算,加载寄存器中的多个连续浮点数。
NumPy中的矩阵计算可以采用多线程的方式,充分利用多核CPU计算资源,大大提升了计算效率。python因为有GIL锁,因此多线程也只能使用一个处理器,但是numpy是例外,因为numpy内部是用C写的,不经过python解释器,因此它本身的矩阵运算(array operations)都可以使用多核。
除了使用 NumPy外,你还需要一些技巧来提升内存和提高计算资源的利用率。一个重要的规则就是:避免采用隐式拷贝,而是采用就地操作的方式。举个例子,如果我想让一个数值x是原来的两倍,可以直接写成x =2,而不要写成y=x 2。这样速度能快2倍甚至更多。
NumPy里有两个重要的对象:ndarray(N-dimensional array object)解决了多维数组问题。ufunc(universal function object)则是解决对数组进行处理的函数。
ndarray对象
axis为0是跨行(纵向),axis为1是跨列(横向)。
创建数组

运行结果
结构数组
如果想统计一个班级里面学生的姓名,年龄,以及语文数学英语成绩,可以用数组的下标来代表不同的字段,但是这样不显性,可以自己定义一个数据结构。
运行结果
注意在定义数组时,用array中指定了结构数组的类型dtype=persontype
ufunc运算
它能对数组中每个元素进行函数操作,NumPy中很多ufunc函数计算速度非常快,因为都是采用C语言实现的。
连续数组的创建
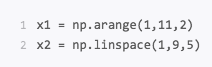
np. arange和np.linspace起到的作用是一样的,都是创建等差数组。这两个数组的结果x1,x2都是[1 3 5 7 9]。结果相同,但是创建的方式是不同的。
arange()类似内置函数 range(),通过指定初始值、终值、步长来创建等差数列的一维数组,默认是不包括终值的。
linspace是 linear space的缩写,代表线性等分向量的含义。 linspace()通过指定初始值,终值、元素个数来创建等差数列的一维数组,默认是包括终值的。
算术运算

运行结果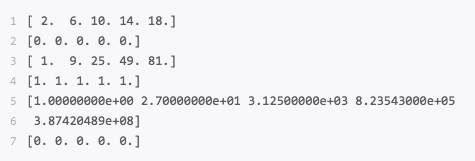
取余函数里,既可以用remainder,也可以用mod,结果是一样的。
统计函数
统计数组矩阵的最大值函数amax(),最小值函数amin()
运行结果
统计最大值与最小值之差ptp()
运行结果
统计数组的百分位数percentile()
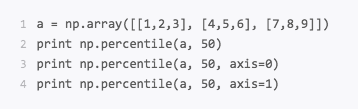
运行结果
percentile()代表着第p个百分位数,这里p的取值范围是0-100,如果p=0,那么就是求最小值,如果p=50就是求平均值,如果p=100就是求最大值。同样你也可以求得在axs=0和axis=1两个轴上的p%的百分位数。
统计数组中的中位数median(),平均数mean()

运行结果
统计数组中的加权平均值average()

运行结果
统计数组中的标准差std(),方差var()

运行结果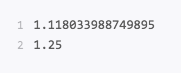
NumPy排序
这些排序算法在NumPy中实现起来其实非常简单,一条语句就可以搞定。这里你可以使用sort函数,sort(a,axis=-1,kind= quicksort, order=None),默认情况下使用的是快速排序;在kind里,可以指定 quicksort、 mergesort、 heapsort分别表示快速排序、合并排序、堆排序。同样axis默认是-1,即沿着数组的最后一个轴迸行排序,也可以取不同的axis轴,或者axis=None代表采用扁平化的方式作为一个向量进行排序。另外 order字段对于结构化的数组可以指定按照某个字段进行排序。
运行结果
练习题
统计全班的成绩
假设一个团队里有5名学员,成绩如下表所示。你可以用 NumPy统计下这些人在语文、英语、数学中的平均成绩、最小成绩、最大成绩、方差、标准差。然后把这些人的总成绩排序,得出名次进行成绩输出。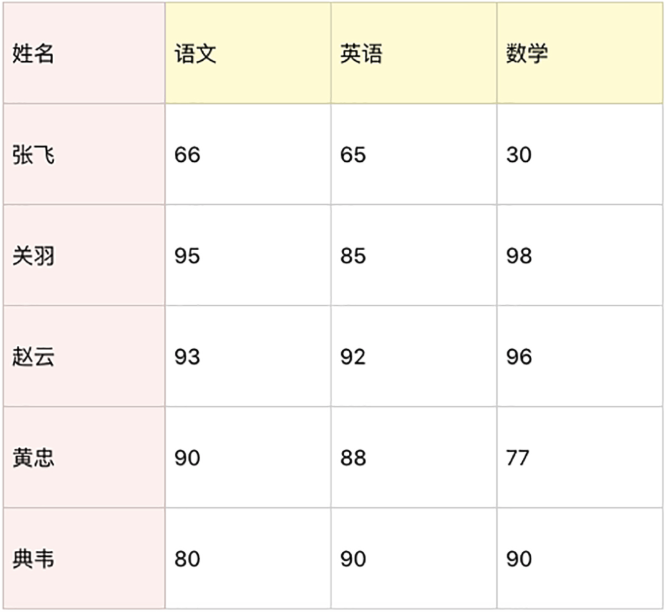
PythonCode/统计全班的成绩.py at master · zdkswd/PythonCode · GitHub
Pandas之再回首

在NumPy中数据结构是围绕ndarray展开的,在Pandas中,核心数据结构是Series和DataFrame。Pandas的基础是NumPy。
数据结构:Series和DataFrame
Series是个定长的字典序列,说是定长是因为在存储时,相当于两个ndarray,这也是和字典结构最大的不同,因为在字典结构中元素的个数是不固定的。
Series有两个基本属性,Index和values。在Series结构中,index默认是0,1,2递增的整数序列,当然也可以自己来指定索引,index=[‘a’, ‘b’, ‘c’, ‘d’]。
运行结果
还可以用字典方式来创建Series。
运行结果
DataFrame类型数据结构类似数据库表
数据库表
DataFrame是由相同索引的Series组成的字典类型。
import pandas as pd
from pandas import Series, DataFrame
data = {‘Chinese’: [66, 95, 93, 90,80],’English’: [65, 85, 92, 88, 90],’Math’: [30, 98, 96, 77, 90]}
df1= DataFrame(data)
df2 = DataFrame(data, index=[‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’], columns=[‘English’, ‘Math’, ‘Chinese’])
print df1
print df2
df1的输出: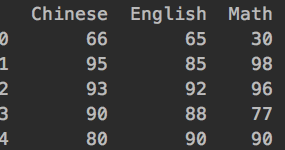
df2的输出: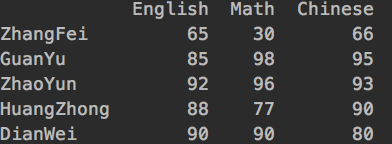
数据导入和输出
xlsx,csv
数据清洗
数据清洗是数据准备中必不可少的环节,Pandas也为我们提供了数据清洗的工具。
删除DataFrame中不必要的行或列
Pandas中drop()方法来删除我们不想要的列或行。
将语文这列删掉
将张飞这行删掉
重命名列名columns,让列表名更容易识别
例如把列名Chinese改为YuWen,English改为YingYu。
去重复的值
数据采集可能存在重复的行,这时只要使用 drop_duplicates就会自动把重复的行去掉。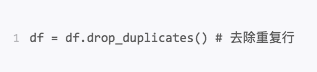
格式问题
更改数据格式
这是个比较常用的操作,因为很多时候数据格式不规范,我们可以使用 astype函数来规范数据格式,比如我们把 Chinese字段的值改成str类型,或者int64可以这么写。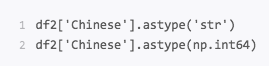
数据间的空格
有时候我们先把格式转成了str类型,是为了方便对数据进行操作,这时想要删除数据间的空格,我们就可以使用strip函数。
想要删除特殊符号,同样可以使用strip函数,比如删除美元符号。
大小写转换

查找空值
数据量大的情况下,有些字段存在空值NaN的可能,这时需要Pandas中的isnull函数进行查找。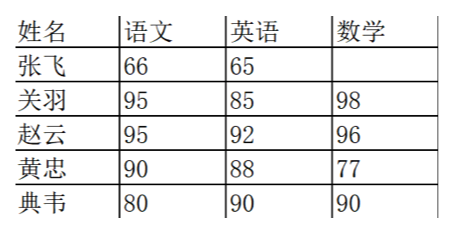
如果想看哪些地方存在空值NaN,可以针对数据表df进行df.isnull()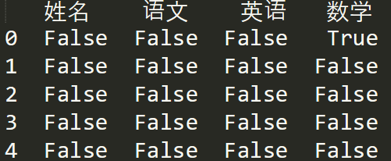
如果想要知道哪列存在空值,可以使用df.isnull().any()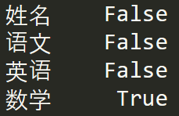
使用apply函数对数据进行清洗
apply是Pandas中自由度非常高的函数,使用频率也非常高。
比如想对name列的数值都进行大写转化:
可以定义个函数,在apply中进行使用。
还可以定义更复杂的函数
其中axis=1代表按照列为轴进行操作,axis=0代表按照行为轴进行操作,args是传递的两个参数,即n=2,m=3,在plus函数中使用到了n和m,从而生成新的df。
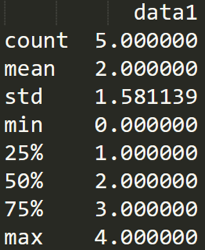
数据统计
在数据清洗后,就要对数据进行统计了。Pandas和NumPy一样都有常用的统计函数,如果遇到空值NaN,会自动排除。

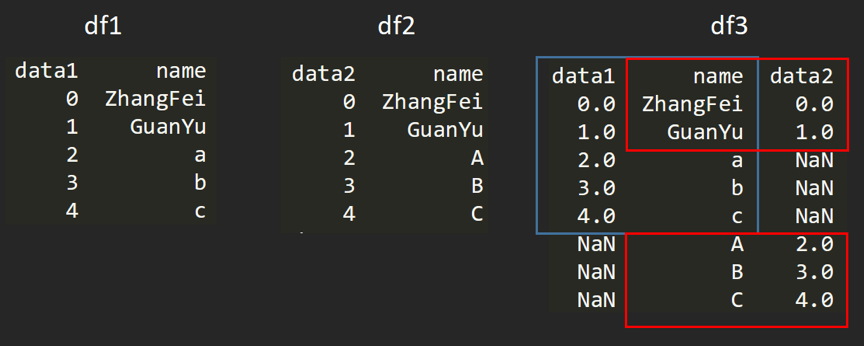
数据表合并
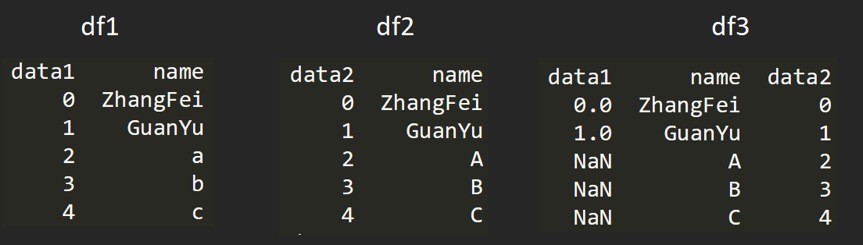
创建两个DataFrame。
使用的是merge()函数,有五种形式。
基于指定列进行连接


inner内连接


left左连接
左连接是第一个DataFrame为主进行连接,第二个DataFrame作为补充。

right右连接
右连接是以第二个DataFrame为主进行的连接,第一个DataFrame作为补充。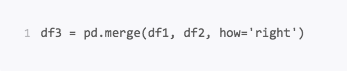
outer外连接
外连接相当于求两个DataFrame的并集。
用SQL方式打开Pandas
pandasql。
pandas中的主要函数是sqdf,它接收两个参数:一个SQL查询语句,还有一组环境变量globals()或 locals()。这样我们就可以在 Python里,直接用SQL语句中对 Data Frame进行操作,举个例子。
运行结果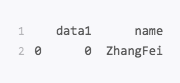
其中lambda是用来定义一个匿名函数的。具体形式为: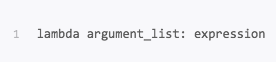
argument_list 是参数列表,expression是关于参数的表达式,会根据expression表达式计算结果进行输出返回。