网络爬虫
参考https://cuijiahua.com/blog/2017/10/spider_tutorial_1.html
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
- urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
- requests库是第三方库,需要我们自己安装。
requests库的基础方法如下: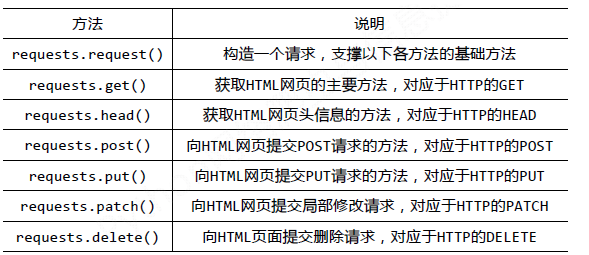
requests.get()方法,它用于向服务器发起GET请求。requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。
小说下载
代码papapachong/爬取小说 at master · zdkswd/papapachong · GitHub
背景
小说网站-笔趣看:
URL:http:www.biqukan.com/
笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。因此,本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说,该小说是耳根正在连载中的一部玄幻小说。PS:本实例仅为交流学习,支持耳根大大,请上起点中文网订阅。
小试牛刀
《一念永恒》小说的第一章内容,URL:http://www.biqukan.com/1_1094/5403177.html
通过result=rq.get(url=target)
我们很轻松地获取了HTML信息。但是,很显然,很多信息是我们不想看到的,我们只想获得如右侧所示的正文内容,我们不关心div、br这些html标签。如何把正文内容从这些众多的html标签中提取出来呢?这就是本次实战的主要内容。
Beautiful Soup
爬虫的第一步,获取整个网页的HTML信息,我们已经完成。接下来就是爬虫的第二步,解析HTML信息,提取我们感兴趣的内容。对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup等。对于初学者而言,最容易理解,并且使用简单的方法就是使用Beautiful Soup提取感兴趣内容。
Beautiful Soup中文的官方文档。URL:
http://beautifulsoup.readthedocs.io/zh_CN/latest/
仔细观察目标网站一番,我们会发现这样一个事实:class属性为showtxt的div标签,独一份!这个标签里面存放的内容,是我们关心的正文部分。
知道这个信息,我们就可以使用Beautiful Soup提取我们想要的内容了。
在解析html之前,我们需要创建一个Beautiful Soup对象。BeautifulSoup函数里的参数就是我们已经获得的html信息。然后我们使用find_all方法,获得html信息中所有class属性为showtxt的div标签。find_all方法的第一个参数是获取的标签名,第二个参数class_是标签的属性,为什么不是class,而带了一个下划线呢?因为python中class是关键字,为了防止冲突,这里使用class_表示标签的class属性。
为什么不是find_all(‘div’, id = ‘content’, class_ = ‘showtxt’)?这样其实也是可以的,属性是作为查询时候的约束条件,添加一个class_=’showtxt’条件,我们就已经能够准确匹配到我们想要的标签了,所以我们就不必再添加id这个属性了。
此时结果中有一些我们不想要的东西。比如div标签名,br标签,以及各种空格。怎么去除这些东西呢?
find_all匹配的返回的结果是一个列表。提取匹配结果后,使用text属性,提取文本内容,滤除br标签。随后使用replace方法,剔除空格,替换为回车进行分段。 在html中是用来表示空格的。replace(‘\xa0’*8,’\n\n’)就是去掉下图的八个空格符号,并用回车代替。
可以看到,我们很自然的匹配到了所有正文内容,并进行了分段。我们已经顺利获得了一个章节的内容,要想下载正本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
URL:http:www.biqukan.com/1_1094/
根据 标签的href属性值获得每个章节的链接和名称。小说每章的链接放在了class属性为listmain的
爬取壁纸
papapachong/爬取图片 at master · zdkswd/papapachong · GitHub
背景
URL:https:unsplash.com/
网站的名字叫做Unsplash,免费高清壁纸分享网是一个坚持每天分享高清的摄影图片的站点,每天更新一张高质量的图片素材,全是生活中的景象作品,清新的生活气息图片可以作为桌面壁纸也可以应用于各种需要的环境。
实战
- 使用requeusts获取整个网页的HTML信息;
- 使用Beautiful Soup解析HTML信息,找到所有
标签,提取src属性,获取图片存放地址;
- 根据图片存放地址,下载图片。
照此方法得不到标签,而是\<script>标签,因为这个网站的所有图片都是动态加载的!网站有静态网站和动态网站之分,上一个实战爬取的网站是静态网站,而这个网站是动态网站,动态加载有一部分的目的就是为了反爬虫。
动态网站使用动态加载常用的手段就是通过调用JavaScript来实现的。一个动态加载的网站可能使用很多JavaScript脚本,我们只要找到负责动态加载图片的JavaScript脚本。强大的抓包工具,它会帮助分析。这个强大的抓包工具就是Fiddler。但是Fiddler只在Windows上才能发挥完全的作用,所以我用的是一个跨平台的抓包工具Charles。
经过抓包发现,在如下数据包中。
有json数据包
id和下载图片有以下的关系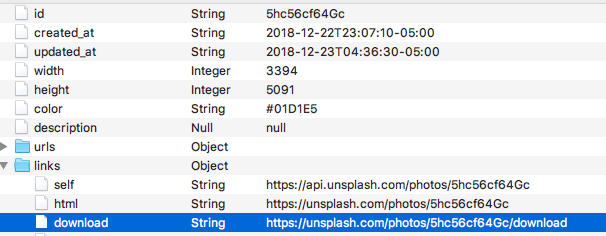
所以可以
- 获取整个json数据
- 解析json数据
如果直接获取会出现SSL认证的错误,SSL认证是指客户端到服务器端的认证。一个非常简单的解决这个认证错误的方法就是设置requests.get()方法的verify参数。这个参数默认设置为True,也就是执行认证。我们将其设置为False,绕过认证。
反爬虫的手段除了动态加载,还有一个反爬虫手段,那就是验证Request Headers。Requests Headers里有很多参数,有Accept、Accept-Encoding、Accept-Language、DPR、User-Agent、Viewport-Width、accept-version、Referer、x-unsplash-client、authorization、Connection、Host。
- User-Agent:这里面存放浏览器的信息。如果我们不设置这个参数,用Python程序直接发送GET请求,服务器接受到的User-Agent信息就会是一个包含python字样的User-Agent。如果后台设计者验证这个User-Agent参数是否合法,不让带Python字样的User-Agent访问,这样就起到了反爬虫的作用。这是一个最简单的,最常用的反爬虫手段。
- Referer:这个参数也可以用于反爬虫,它表示这个请求是从哪发出的。可以看到我们通过浏览器访问网站,这个请求是从https://unsplash.com/,这个地址发出的。如果后台设计者,验证这个参数,对于不是从这个地址跳转过来的请求一律禁止访问,这样就也起到了反爬虫的作用。
- authorization:这个参数是基于AAA模型中的身份验证信息允许访问一种资源的行为。在我们用浏览器访问的时候,服务器会为访问者分配这个用户ID。如果后台设计者,验证这个参数,对于没有用户ID的请求一律禁止访问,这样就又起到了反爬虫的作用。
Unsplash是根据authorization参数进行反爬虫的。通过程序手动添加这个参数,然后再发送GET请求,就可以顺利访问了。即requests.get()方法,添加headers参数即可。
现在终于顺利获得json数据了,使用json.load()方法解析数据。解析json数据很简单,跟字典操作一样,就是字典套字典。json.load()里面的参数是原始的json格式的数据。
图片的ID已经获得了,再通过字符串处理一下,就生成了我们需要的图片下载请求地址。根据这个地址,我们就可以下载图片了。下载方式,使用直接写入文件的方法。
每次获取链接加一个1s延时,因为人在浏览页面的时候,翻页的动作不可能太快。我们要让我们的爬虫尽量友好一些。
下载速度还行,有的图片下载慢是因为图片太大。可以看到也打印了一些警报信息,这是因为没有进行SSL验证。
爱奇艺VIP视频下载
现在失效了,只能手动抓包了
papapachong/爬取视频 at master · zdkswd/papapachong · GitHub
vip视频解析,vip视频在线解析有效的url解析网站。
解析格式:www.wq114.org/yun.php?url= [视频url]
利用网络爬虫进行抓包,可以将视频下载下来。
HTTP请求头Referer的作用:表示请求来源。
编写代码的时候注意一个问题,就是我们需要使用requests.session()保持我们的会话请求。简单理解就是,在初次访问服务器的时候,服务器会给你分配一个身份证明。我们需要拿着这个身份证去继续访问,如果没有这个身份证明,服务器就不会再让你访问。这也就是这个服务器的反爬虫手段,会验证用户的身份。
selenium和xpath
https://github.com/zdkswd/papapachong/tree/master/%E5%AE%89%E5%B1%85%E5%AE%A2