https://arxiv.org/abs/1709.09018
摘要
自动编码是一个重要的任务,通常由深度神经网络比如CNN来实现。在这篇论文中,我们提出了EncoderForest (eForest)这是第一个基于树集成的自编码器。我们提出了一种方法,让森林能够利用树的决策路径所定义的等效类来进行后向重建,并在监督和无监督环境中展示了其使用情况。实验结果表明,与DNN自编码器相比,eForest能够以较快的训练速度获得更低的重建误差,同时模型本身具有可重用性和容损性。
引言
自动编码器是一类将输入数据映射到隐藏空间,然后再映射到原始空间的模型,它使用重建误差作为目标函数。自动编码器分为两个过程:编码和解码。编码过程将原始数据映射到隐藏空间,解码数据将数据从隐藏空间映射到原始数据空间。传统实现这两个过程的方式是使用神经网络。
文章提出了一种编码森林(EncoderForest),通过一个集成树模型进行前向编码和反向解码,而且可以使用监督或者无监督训练。实验显示EncoderFroest有如下优点:
- 准确: 它的实验重建误差比使用MLP和CNN的自动编码器低。
- 有效: efroest在一个单一KNL(多核CPU)上运行比CNN-Base自动编码器在一个Titan-X GPU上运行还快。
- 容错率:训练好的模型能够正常运行即使模型部分损坏。
- 重利用: 在同一个领域下,使用一个数据集训练的模型可以直接应用到另一个数据集下。
模型
自动编码器有两个基本的功能,编码和解码。对于一个森林来说,编码并不困难,因为至少其叶节点信息可以被看做一种编码,甚至可以说,结点集合的一个子集或者路径的分支都能够为编码提供更多的信息。
编码过程
对于给定的一个训练过的有T棵树的集成树模型(也可以是空的森林,编码过程即森林形成过程),前向编码过程将输入数据送到每棵树的根节点,并计算每棵树,得到其所属的叶节点,最后返回一个T维向量,这个T维向量的每一项是每棵树中求到的上述叶节点在树中的编号。注意,算法跟决策树的分割规则无关。只需要是T棵树即可。
解码过程
一般来说,决策树都是用来前向预测,将数据计算从树的根节点到叶子结点,但是其反向重建是未定义的。下面通过一个小例子来探索解码过程。
假设我们正在解决一个二分类问题,数据有三个属性,第一个和第二个属性是数值型属性,第三个属性是布尔型属性(取值为YES, NO),第四个属性是一个三值属性,取值可以是RED,BLUE,GREEN。给定一个实例x,xi代表x的第i个属性值。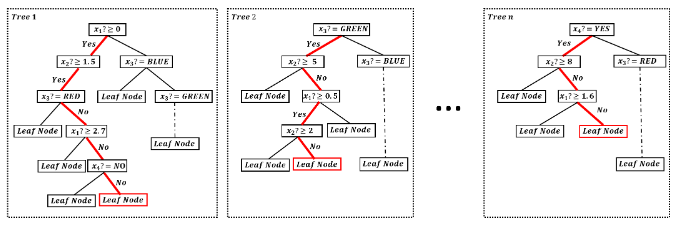
现在我们只知道,实例x落在每棵树的哪个结点,上图中的红色结点,我们的目标是重构实例x。文章提出了一种简洁有效的反向重建方法。首先,在树中的每个叶子结点对应于一条唯一的从根到叶子的路径。在上面的图中已经用红色标出这样的路径。然后,每条路径都会对应一条符号规则,所以我们就得到
了n条(树的数目)符号规则: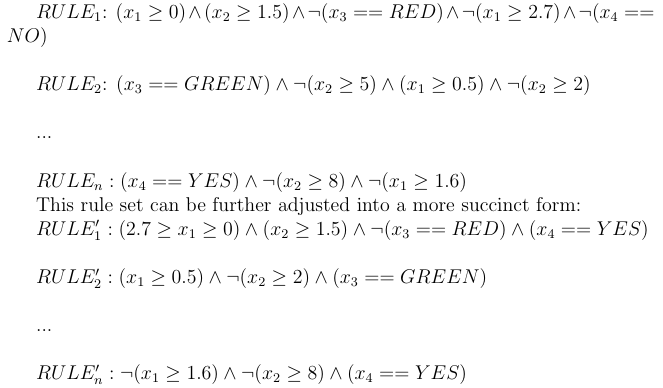
然后,我们可以根据上面的规则推出MCR(最大完备规则),最大完备规则的意思是,在规则中的每一个约束的范围不能再扩大。如果扩大,则会产生冲突。
例如,由上面的规则集我们可以得到MCR: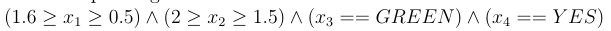
那么显然,原始的数据肯定落在有MCR定义的范围内。
计算完MCR之后,就可以根据MCR重构原始样本了,目录型属性如上面的第三和第四属性只需要根据MCR中的指定取即可,而数值型属性则可以根据MCR中的范围取一个特殊值即可(中位数、均值、或者最大最小值)。
首先根据编码完的T维向量从树中得到T个决策规则,再根据这些规则得到MCR,再根据MCR重构得到x,算法如下:
实验
