GBDT
gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征。
GBDT如何选择特征
gbdt选择特征的细节其实是想问你CART Tree生成的过程。这里有一个前提,gbdt的弱分类器默认选择的是CART TREE。其实也可以选择其他弱分类器的,选择的前提是低方差和高偏差。框架服从boosting 框架即可。
GBDT如何构建特征
其实说gbdt 能够构建特征并非很准确,gbdt 本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。逻辑回归本身是适合处理线性可分的数据,如果我们想让逻辑回归处理非线性的数据,其中一种方式便是组合不同特征,增强逻辑回归对非线性分布的拟合能力。
GBDT如何用于分类
GBDT 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树。
GB训练强学习器的思路




GBDT原理
对于任意的基分类器都可以利用GB的思想训练一个强分类器。而把基分类器选为决策树(DT)时,就是我们常用的GBDT。
对于回归任务,当选择的loss function为Least-square。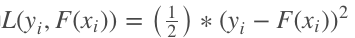
伪代码为:

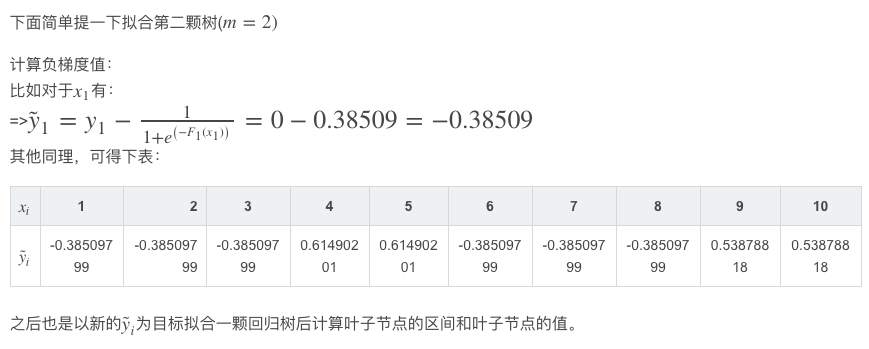
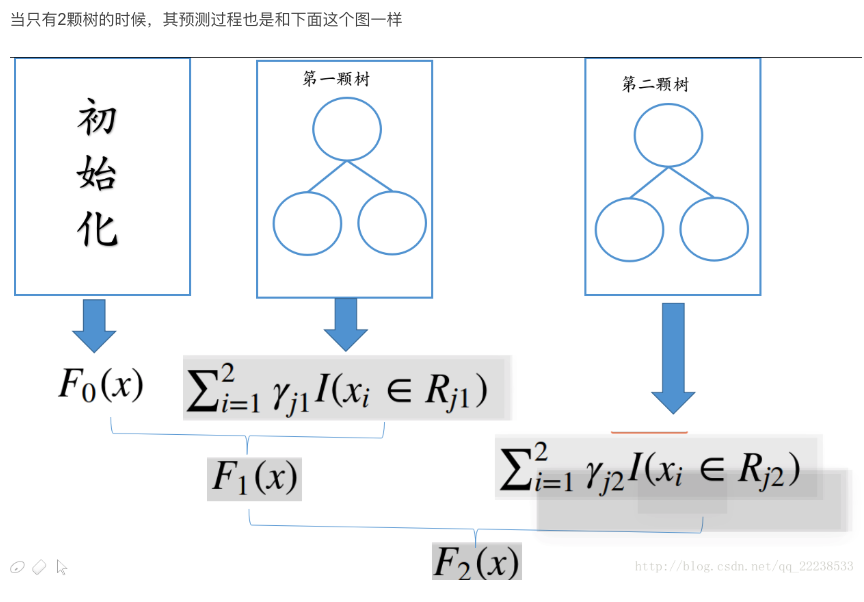
GBDT例


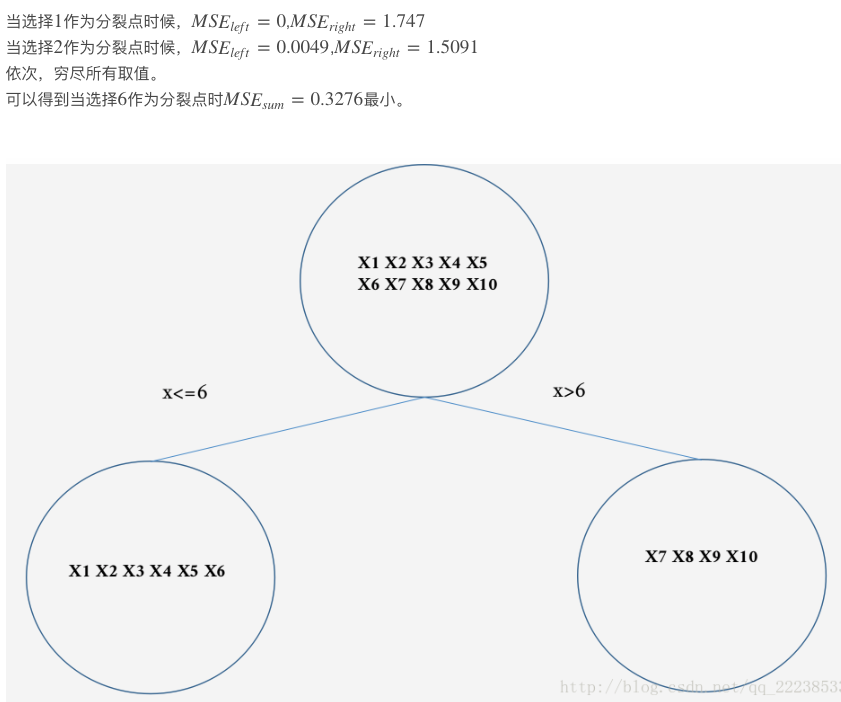


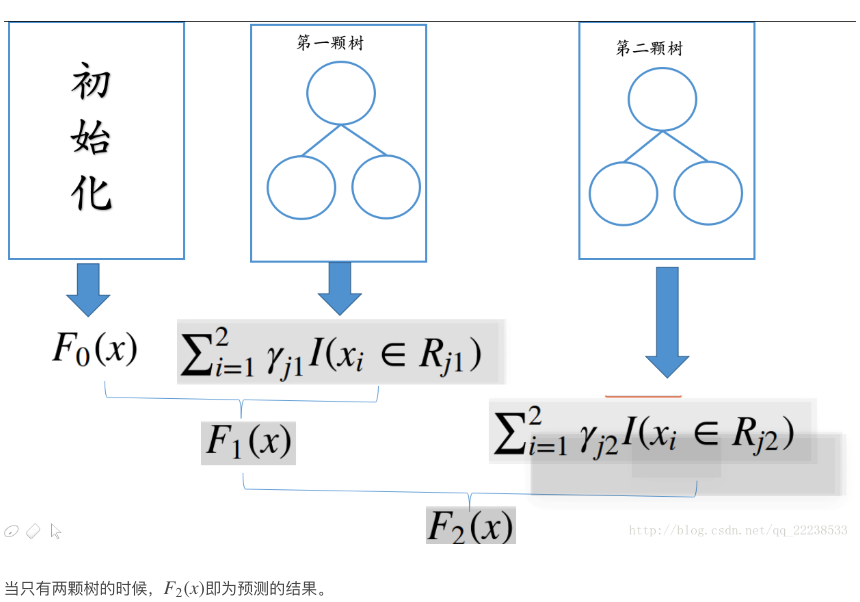
GDBT分类篇
对于回归和分类,其实GBDT过程简直就是一模一样的。如果说最大的不同的话,那就是在于由于loss function不同而引起的初始化不同、叶子节点取值不同。
分类例
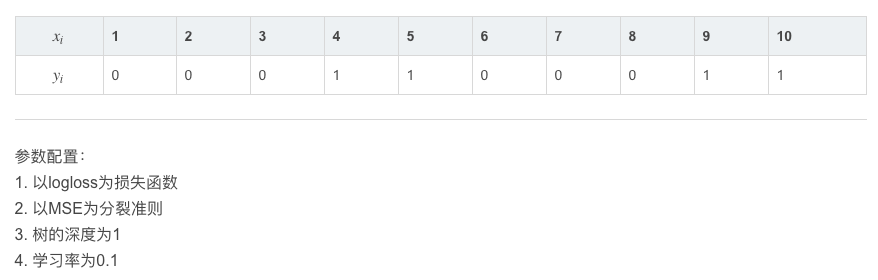
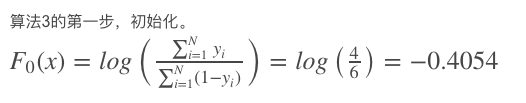



多分类:GBDT原理与实践-多分类篇 - SCUT_Sam - CSDN博客
GBDT+LR
背景
CTR预估(Click-Through Rate Prediction)是互联网计算广告中的关键环节,预估准确性直接影响公司广告收入。CTR预估中用的最多的模型是LR(Logistic Regression),LR是广义线性模型,与传统线性模型相比,LR使用了Logit变换将函数值映射到0~1区间,映射后的函数值就是CTR的预估值。LR这种线性模型很容易并行化,处理上亿条训练样本不是问题,但线性模型学习能力有限,需要大量特征工程预先分析出有效的特征、特征组合,从而去间接增强LR的非线性学习能力。
LR模型中的特征组合很关键, 但又无法直接通过特征笛卡尔积解决,只能依靠人工经验,耗时耗力同时并不一定会带来效果提升。如何自动发现有效的特征、特征组合,弥补人工经验不足,缩短LR特征实验周期,是亟需解决的问题。Facebook 2014年的文章介绍了通过GBDT(Gradient Boost Decision Tree)解决LR的特征组合问题,随后Kaggle竞赛也有实践此思路,GBDT与LR融合开始引起了业界关注。
GBDT(Gradient Boost Decision Tree)是一种常用的非线性模型,它基于集成学习中的boosting思想,每次迭代都在减少残差的梯度方向新建立一颗决策树,迭代多少次就会生成多少颗决策树。GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合,决策树的路径可以直接作为LR输入特征使用,省去了人工寻找特征、特征组合的步骤。这种通过GBDT生成LR特征的方式(GBDT+LR),业界已有实践(Facebook,Kaggle-2014),且效果不错,是非常值得尝试的思路。
融合前人工寻找有区分性特征(raw feature)、特征组合、融合后直接通过黑盒子(Tree模型GBDT)进行特征、特种组合的自动发现。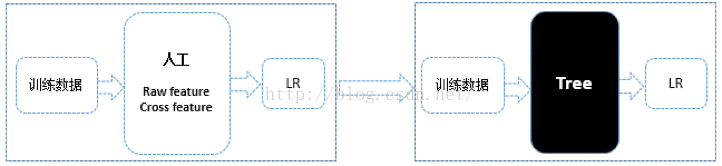
在介绍这个模型之前,我们先来介绍两个问题:
- 为什么要使用集成的决策树模型而不是单颗的决策树模型:
一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少颗树。按paper以及Kaggle竞赛中的GBDT+LR融合方式,多棵树正好满足LR每条训练样本可以通过GBDT映射成多个特征的需求。 - 为什么建树采用GBDT而非RF:RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
GBDT+LR的结构
GBDT用来对训练集提取特征作为新的训练输入数据,LR作为新训练输入数据的分类器。
具体步骤:
- GBDT首先对原始训练数据做训练,得到一个二分类器,当然这里也需要利用网格搜索寻找最佳参数组合。
- 与通常做法不同的是,当GBDT训练好做预测的时候,输出的并不是最终的二分类概率值,而是要把模型中的每棵树计算得到的预测概率值所属的叶子结点位置记为1,这样,就构造出了新的训练数据。在用GBDT构造新的训练数据时,采用的正是One-hot方法。并且由于每一弱分类器有且只有一个叶子节点输出预测结果,所以在一个具有n个弱分类器、共计m个叶子结点的GBDT中,每一条训练数据都会被转换为1*m维稀疏向量,且有n个元素为1,其余m-n 个元素全为0。
- 新的训练数据构造完成后,下一步就要与原始的训练数据中的label(输出)数据一并输入到Logistic Regression分类器中进行最终分类器的训练。思考一下,在对原始数据进行GBDT提取为新的数据这一操作之后,数据不仅变得稀疏,而且由于弱分类器个数,叶子结点个数的影响,可能会导致新的训练数据特征维度过大的问题,因此,在Logistic Regression这一层中,可使用正则化来减少过拟合的风险,在Facebook的论文中采用的是L1正则化。
GBDT与LR的融合方式,Facebook的paper有个例子如下图2所示,图中Tree1、Tree2为通过GBDT模型学出来的两颗树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR一维特征,那么通过遍历树,就得到了该样本对应的所有LR特征。由于树的每条路径,是通过最小化均方差等方法最终分割出来的有区分性路径,根据该路径得到的特征、特征组合都相对有区分性,效果理论上不会亚于人工经验的处理方式。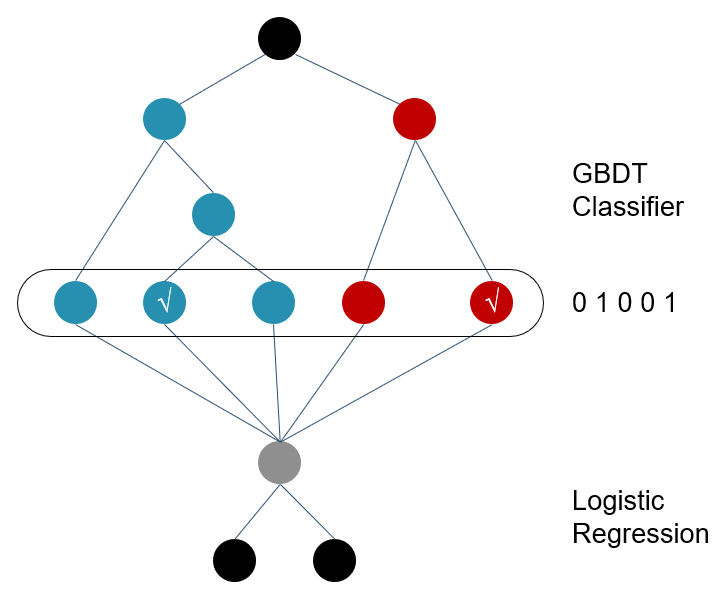
论文中GBDT的参数,树的数量最多500颗(500以上就没有提升了),每棵树的节点不多于12。
GBDT模型的特点,非常适合用来挖掘有效的特征、特征组合。业界不仅GBDT+LR融合有实践,GBDT+FM也有实践,2014 Kaggle CTR竞赛冠军就是使用GBDT+FM(因子分解机),可见,使用GBDT融合其它模型是非常值得尝试的思路。
RF + LR ? Xgb + LR?
例如Random Forest以及Xgboost等是并不是也可以按类似的方式来构造新的训练样本呢?没错,所有这些基于树的模型都可以和Logistic Regression分类器组合。
RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
GBDT与LR融合具体方案
在CTR预估中,如何利用AD ID是一个问题。直接将AD ID作为特征建树不可行,而onehot编码过于稀疏,为每个AD ID建GBDT树,相当于发掘出区分每个广告的特征。而对于曝光不充分的样本即长尾部分,无法单独建树。
综合方案为:使用GBDT对非ID和ID分别建一类树。
- 非ID类树:
不以细粒度的ID建树,此类树作为base,即这些ID一起构建GBDT。即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合。 - ID类树:
以细粒度 的ID建一类树(每个ID构建GBDT),用于发现曝光充分的ID对应有区分性的特征、特征组合。
如何根据GBDT建的两类树,对原始特征进行映射?当一条样本x进来之后,遍历两类树到叶子节点,得到的特征作为LR的输入。当AD曝光不充分不足以训练树时,其它树恰好作为补充。

通过GBDT转换得到特征空间相比于原始ID低了很多。
如何使用得到的特征?
通过GBDT生成的特征,可直接作为LR的特征使用,省去人工处理分析特征的环节,LR的输入特征完全依赖于通过GBDT得到的特征。此思路已尝试,通过实验发现GBDT+LR在曝光充分的广告上确实有效果,但整体效果需要权衡优化各类树的使用。同时,也可考虑将GBDT生成特征与LR原有特征结合起来使用,待尝试。
总结
对于样本量大的数据,线性模型具有训练速度快的特点,但线性模型学习能力限于线性可分数据,所以就需要特征工程将数据尽可能地从输入空间转换到线性可分的特征空间。GBDT与LR的融合模型,其实使用GBDT来发掘有区分度的特征以及组合特征,来替代人工组合特征
GBDT + LR 代码
sklearn多种模型ROC比较
MLcode/sklearn-gbdt+lr.py at master · zdkswd/MLcode · GitHub