机器学习:问题背景
学习问题分以下几类:
有监督学习
分类
回归
无监督学习
聚类,密度估计等
加载示例数据集
有几个标准数据集,鸢尾花和手写字用于分类,以及波士顿房价数据集用于回归。
鸢尾花与手写字数据集的导入。
数据集就是一个字典对象,包含了所有的数据以及一些关于数据的元数据。数据存储在.data成员中,它是一个n个样本,n个特征的数组。在监督学习的问题中,因变量存在.target成员中。

数据数组的形状
数据总是二维数组,(n_sample,n_features)的形状,即使原始数据可能有着不同的形状。在手写字识别中,每个原始例子是(8 * 8)。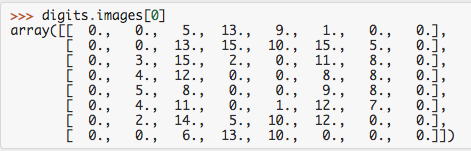
但是在data中变成了(1 * 64)。
学习以及预测
在scikit-learn中,分类器是一个实现了方法fit(x,y)和predict(T)的Python对象。
先把分类器当做是一个黑盒。
选择模型的参数
在这个例子中我们是人工选择的参数,为了寻找这些参数的更好的值,我们能使用例如网格搜索和交叉验证的工具。
分类器实例拟合模型是通过传递训练集给fit方法。对于训练集,我们使用除了最后一张图片的所有图片,最后一张图片用来做预测。
来预测:
模型持久化
使用pickle。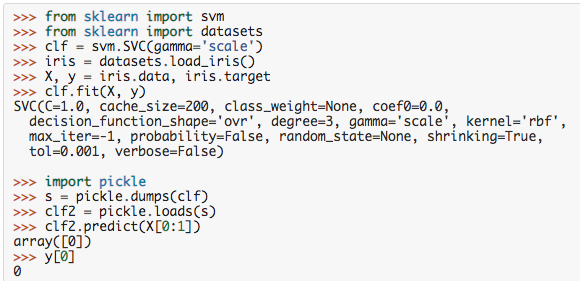
使用joblib,joblib在大数据方面更加高效,但是遗憾的是它只能把数据持久化到硬盘而不是字符串(搬到字符串意味着数据在内存中)。
之后可以重新加载模型(也可以在其他的Python进程中)
注意:joblib.dump和joblib.load也接收像文件一样的对象而不是文件名。
惯例
类型转换
除非特别指明,输入将被转换为float64:
x是float32型,可以通过fit_transform(x)转换为float64。
回归的目标类型转化为float64,分类的目标类型保留下来。
改装和更新参数
超参数在通过set_params()方法创建后能够更新。调用fit()函数超过一次将会重写之前fit()所学的内容。
多类别vs多标签拟合
当使用多类别分类器,所执行的学习和预测任务取决于适合于目标数据的格式。