系统架构
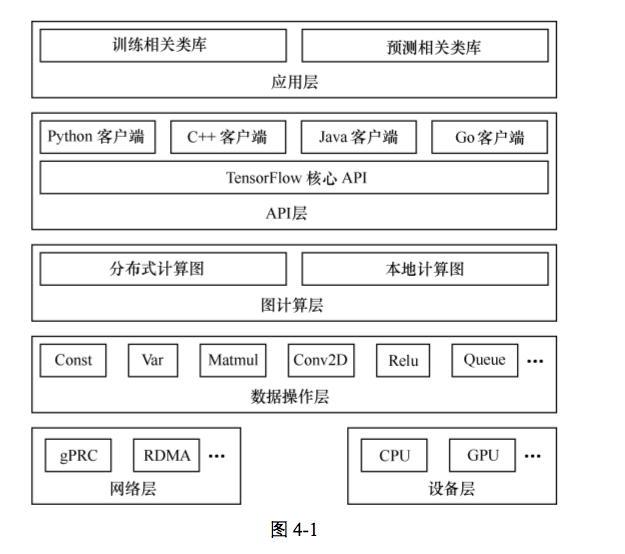
自底向上为设备层和网络层、数据操作层、图计算层、API层、应用层。
其中设备层和网络层、数据操作层、图计算层是TensorFlow的核心层。
网络通信层和设备管理层
网络通信层包括gRPC( google Remote Procedure Call Protocol)和远程直接数据存取( Remote direct Memory Access,RDMA),这都是在分布式计算时需要用到的。设备管理层包括 TensorFlow分别在CPU、GPU、FPGA等设备上的实现,也就是对上层提供了一个统一的接口,使上层只需要处理卷积等逻辑,而不需要关心在硬件上的卷积的实现过程。
数据操作层
主要包括卷积函数、激活函数等操作。
图计算层(了解的核心)
包含本地计算图和分布式计算图的实现。
API层和应用层
设计理念
TensorFlow的设计理念主要体现在以下两个方面。
将图的定义和图的运行完全分开
编程模式通常分为命令式编程和符号式编程。命令式编程就是我们理解的通常意义上的程序,很容易理解和调试,按照原有的逻辑执行。符号式编程涉及很多的嵌入和优化,不容易理解和调试,但运行速度相对有所提升。现有的深度学习框架中, Torch是典型的命令式的,Cafe、 MXNet采用了两种编程模式混合的方法,而 TensorFlow完全釆用符号式编程。
符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译,但此时的数据流图还是一个空壳儿,里面没有任何实际数据,只有把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
在传统的程序操作中,定义了t的运算,在运行时就执行了,并输出17。而在TensorFlow中,数据流图中的节点,实际上对应的是 Tensor Flow APi中的一个操作,并没有真正去运行:
TensorFlow中涉及的运算都要放在图中,而图的运行只发生在会话( session)中
开启会话后,就可以用数据去填充节点,进行运算;关闭会话后,就不能进行计算了。因此,会话提供了操作运行和 Tensor求值的环境。
编程模型
边
TensorFlow的边有两种连接关系:数据依赖和控制依赖。
实线边表示数据依赖
代表数据,即张量。任意纬度的数据统称为张量。在机器学习算法中,张量在数据流图中从前往后流动一遍就完成了一次前向传播,而残差从后向前流动一遍就完成了一次反向传播。(在数理统计中,残差是指实际观察值与训练的估计值之间的差。)
虚线边表示控制依赖(control dependency )
可以用于控制操作的运行,这被确保happens-before关系,这类边上没有数据流过,但源节点必须在目的节点开始执行前完成执行。
TensorFlow 支持的张量具有表 4-1 所示的数据属性。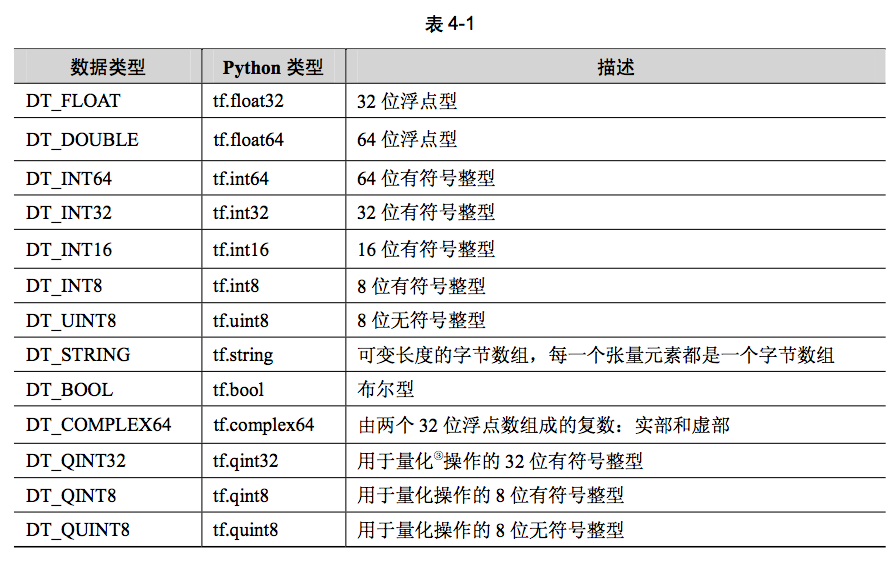
节点
图中的节点又称为算子,它代表一个操作(operation,OP),一般用来表示施加的数学运算,也可以表示数据输入(feed in)的起点以及输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。 表 4-2 列举了一些 TensorFlow 实现的算子。算子支持表 4-1 所示的张量的各种数据属性,并且需要在建立图的时候确定下来。
与操作相关的代码位于 tensorflow-1.1.0/tensorflow_python_ops_目录下。以数学运算为例,代 码为上述目录下的 math_ops.py,里面定义了 add、subtract、multiply、scalar_mul、div、divide、 truediv、floordiv 等数学运算,每个函数里面调用了 gen_math_ops.py 中的方法,这个文件是在 编译(安装时)TensorFlow 时生成的,位于 Python 库 site-packages_tensorflow_python_ops_gen_ math_ops.py 中,随后又调用了 tensorflow-1.1.0_tensorflow_core_kernels/下面的核函数实现。
其他概念
图
把操作任务描述成有向无环图。构建图的第一步是创建各个节点。
会话
启动图的第一步是创建一个 Session对象。会话( session)提供在图中执行操作的一些方法。一般的模式是,建立会话,此时会生成一张空图,在会话中添加节点和边,形成一张图,然后执行。
要创建一张图并运行操作的类,在 Python的API中使用tf. Session,在C++的API中使用tensorflow: Session。
在调用 Session对象的run()方法来执行图时,传入一些 Tensor,这个过程叫填充(feed)返回的结果类型根据输入的类型而定,这个过程叫取回( fetch)。
与会话相关的源代码位于 tensorfow-11.0/ tensorfow/ python/ client/session. py。
会话是图交互的一个桥梁,一个会话可以有多个图,会话可以修改图的结构,也可以往图中注入数据进行计算。因此,会话主要有两个AP接口: Extend和Run。 Extend操作是在 Graph中添加节点和边,Run操作是输入计算的节点和填充必要的数据后,进行运算,并输出运算结果。
设备
设备(device)是指一块可以用来运算并且拥有自己的地址空间的硬件,如GPU和CPU。
TensorFlow为了实现分布式执行操作,充分利用计算资源,可以明确指定操作在哪个设备上执行。
与设备相关的源代码位于 tensorfow-1.1.0 tensorflow_python_ framework/device. py。
变量
变量( variable)是一种特殊的数据,它在图中有固定的位置,不像普通张量那样可以流动。例如,创建一个变量张量,使用tf.Variable()构造函数,这个构造函数需要一个初始值,初始值的形状和类型决定了这个变量的形状和类型。
创建一个常量张量:
TensorFlow还提供了填充机制,可以在构建图时使用tf.placeholder临时替代任意操作的张量,在调用 Session对象的run()方法去执行图时,使用填充数据作为调用的参数,调用结束后,填充数据就消失。
与变量相关的源代码位于 tensorflow/ tensorflow/ python_ops_ variables. py。
内核
我们知道操作( operation)是对抽象操作(如 matmul或者ad)的一个统称,而内核( kemel)则是能够运行在特定设备(如CPU、GPU)上的一种对操作的实现。因此,同一个操作可能会对应多个内核。
常用API
图、操作和张量
与图相关的API均位于tf.Graph类中。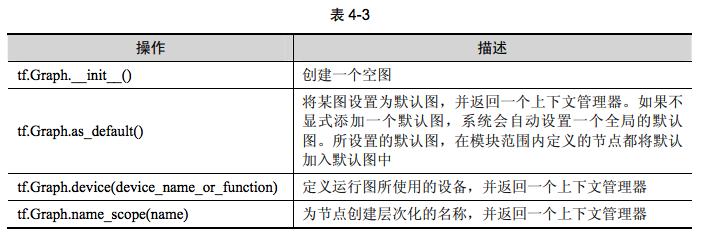
tf.Operation类代表图中的一个节点,用于计算张量数据。该类型由节点构造器(如tf.matmul()或者Graph.create_op())产生。例如,c=tf.matmul(a,b)
创建一个Operation类,其类型为MatMul的操作类。与操作相关的API均位于tf.Operation类中。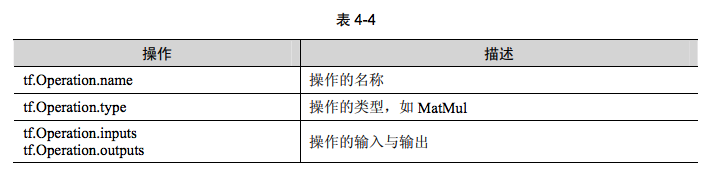

tf.Tensor类是操作输出的符号句柄,它不包含操作输出的值,而是提供了一种在tf.Session中计算这些值的方法。这样就可以在操作之间构建一个数据流连接,使 TensorFlow能够执行一个表示大量多步计算的图形。与张量相关的API均位于tf.Tensor类中。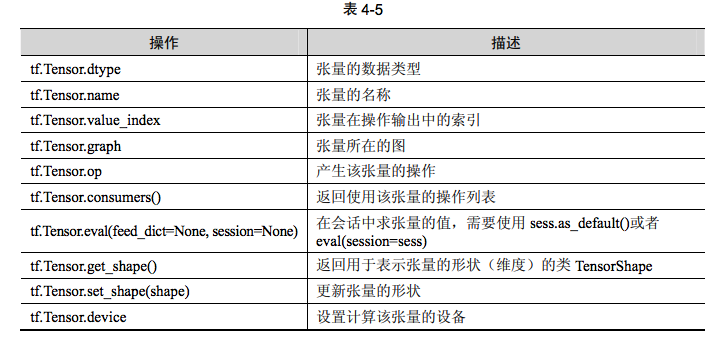
变量作用域
在 TensorFlow中有两个作用域( scope),一个是 name_scope,另一个是 variable_scope。简而言之, name_scope主要是给 variable_name加前缀,也可以给 op_ name加前缀; name_scope是给 op_name加前缀。
variable_scope
variable_scope变量作用域机制在 TensorFlow中主要由两部分组成:
创建或是返回一个变量,或是为变量指定命名空间。
当 tf. get_variable_scope. reuse==False时, variable_scope作用域只能用来创建新变量:
上述程序会抛出ValueError错误,因为v这个变量已经被定义过了,但tf.get_variable_scope().reuse默认为False,所以不能重用。
当tf.get_variable_scope().reuse=True时,作用域可以共享变量:
获取变量作用域
可以直接通过 tf.variable_scope()来获取变量作用域:
如果在开启的一个变量作用域里使用之前预先定义的一个作用域,则会跳过当前变量的作用域,保持预先存在的作用域不变。
变量作用域的初始化
变量作用域可以默认携带一个初始化器,在这个作用域中的子作用域或变量都可以继承或者重写父作用域初始化器中的值。
在variable_scope作用域下的操作op_name也会被加上前缀。

variable scope主要用在循环神经网络(RNN)的操作中,其中需要大量的共享变量。
name_scope示例
TensorFlow中常常会有数以千计的节点,在可视化的过程中很难一下子展示出来,因此用name_scope为变量划分范围,在可视化中,这表示在计算图中的一个层级。name_scope会影响op_name,不会影响get_variableo创建的变量,而会影响通过 Variableo创建的变量。
批标准化
批标准化( batch normalization,BN)是为了克服神经网络层数加深导致难以训练而诞生的我们知道,深度神经网络随着网络深度加深,训练起来会越来越困难,收敛速度会很慢,常常会导致梯度弥散问题( vanishing gradient problem)。
统计机器学习中有一个ICS( Internal Covariate shift)理论,这是一个经典假设:源域( source domain)和目标域( target domain)的数据分布是一致的。也就是说,训练数据和测试数据是满足相同分布的。这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。
Covariate shift是指训练集的样本数据和目标样本集分布不一致时,训练得到的模型无法很好地泛化( generalization)。它是分布不一致假设之下的一个分支问题,也就是指源域和目标域的条件概率是一致的,但是其边缘概率不同。的确,对于神经网络的各层输出,在经过了层内操作后,各层输出分布就会与对应的输入信号分布不同,而且差异会随着网络深度增大而加大,但是每一层所指向的样本标记( label)仍然是不变的。
解决思路一般是根据训练样本和目标样本的比例对训练样本做一个矫正。因此,通过引入批标准化来规范化某些层或者所有层的输入,从而固定每层输入信号的均值与方差。
方法
批标准化一般用在非线性映射(激活函数)之前,对x=Wu+b做规范化,使结果(输出信号各个维度)的均值为0,方差为1。让每一层的输入有一个稳定的分布会有利于网络的训练。
优点
批标准化通过规范化让激活函数分布在线性区间,结果就是加大了梯度,让模型更加大胆地进行梯度下降,于是有如下优点:
- 加大探索的步长,加快收敛的速度。
- 更容易跳出局部最小值。
- 破坏原来的数据分布,一定程度上缓解过拟合。
在遇到神经网络收敛速度很慢或梯度爆炸等无法训练的情况下,都可以尝试用批标准化来解决。
示例
对每层的Wx_plus_b进行批标准化,这个步骤在激活函数之前。
规范化,也可以称为标准化,是将数据按比例缩放,使之落在一个小的特定区间。这里是指数据减去平均值,再除以标准差。
tf.add(a, b) 与 a+b
