Python数据科学手册 NumPy入门
数据集的来源与格式都十分丰富,比如文档集合、图像集合、声音片段集合、数值数据集合,等等。这些数据虽然存在明显的异构性,但是将所有数据简单地看作数字数组非常有助于我们理解和处理数据。
例如,可以将图像(尤其是数字图像)简单地看作二维数字数组,这些数字数组代表各区域的像素值;声音片段可以看做时间和强度的一维数组;文本也可以通过各种方式转化为数值表示,一种可能的转换时用二进制数表示特定单词或单词对出现的频率。不管数据是何种形式,第一步都是将这些数据转化为数值叔祖形式的可分析数据。
正因如此,有效地存储和操作数值数组是数据科学中绝对的基础过程。NumPy(Numerical Python的简称)提供了高效3存储和操作密集数据缓存的接口。
理解Python中的数据类型
Python的类型灵活性指出了一个事实:Python变量不仅是它们的值,还包括了关于值得类型的一些额外信息。
Python整型不仅仅是一个整型
标准的Python实现是用C语言编写的。这意味着每一个Python对象都是一聪明的伪C语言结构体,该结构体不仅包含其值,还有其他信息。例如当我们在Python中定义一个整型,x=10000时,x并不是一个‘原生’整型,而是一个指针,指向一个C语言的复合结构体,结构体里包含了一些值。

这意味着与C语言这样的编译语言的整型相比,在python中存储一个整型会有一些开销。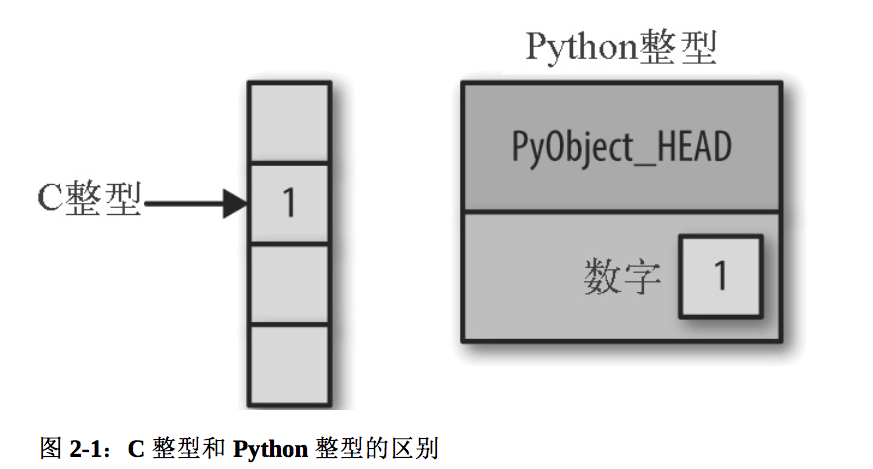
这里PyObject_HEAD是结构体中包含引用计数、类型编码和其他之前提到的内容的部分。
两者的差异在于,C语言整型本质上是对应某个内存位置的标签,里面存储的字节会编码成整型。而Python的整型其实是一个指针,指向包含这个Python对象所有信息的某个内存位置,其中包括可以转换成整型的字节。由于Python的整型结构体中还包含了大量额外的信息,所以Python可以自由、动态地编码,但是Python类型中的这些额外信息也会成为负担,在多个对象组合的结构体中尤其明显。
Python列表不仅仅是一个列表
python中的标准可变多元素容器是列表。为了获得这些灵活的类型,列表中每一项必须包含各自的类型信息、引用计数和其他信息。也就是每一项都是一个完整的Python对象。python的列表甚至可以是异构的,即每项的类型可以不同。如果列表中的所有变量都是同一类型的,那么很多信息会显得多余—将数据存储在固定类型的数组应该会更高效。动态类型的列表和固定类型(NumPy式)数组的区别。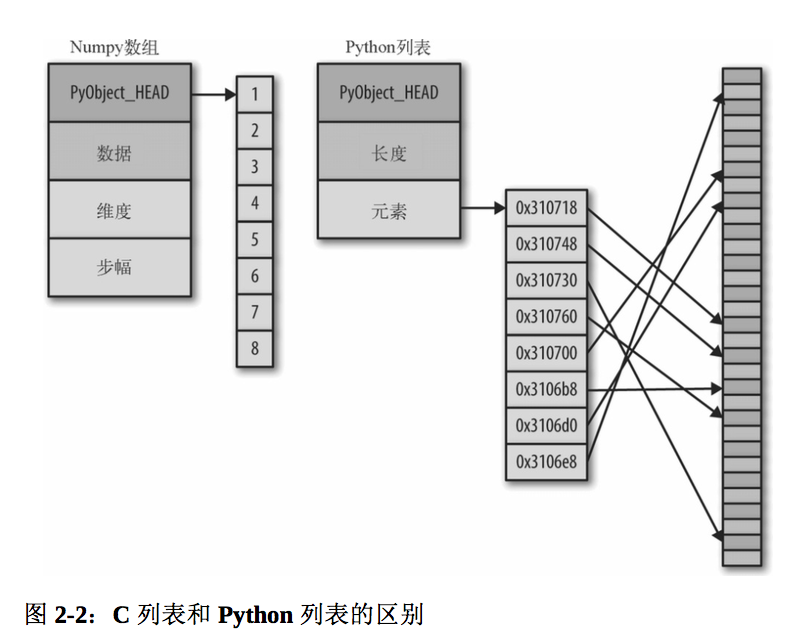
在实现层面,数组基本上包含一个指向连续数据块的指针。另一方面,Python列表包含一个指向指针块的指针,这其中的每一个指针对应一个完整的 Python对象(如前面看到的 Python整型)。另外,列表的优势是灵活,因为每个列表元素是一个包含数据和类型信息的完整结构体,而且列表可以用任意类型的数据填充。固定类型的 NumPy式数组缺乏这种灵活性,但是能更有效地存储和操作数据。
Python中固定类型数组
Python提供了几种将数据存储在有效的、固定类型的数据缓存中的选项。内置的数组( array)模块(在 Python3.3之后可用)可以用于创建统一类型的密集数组:


从Python列表创建数组

最后,不同于Python列表,NumPy数组可以被指定为多维的。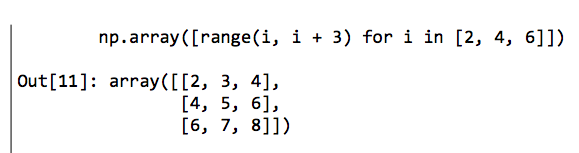
从头创建数组
面对大型数组的时候,用NumPy内置的方法从头创建数组是一种更高效的方法。

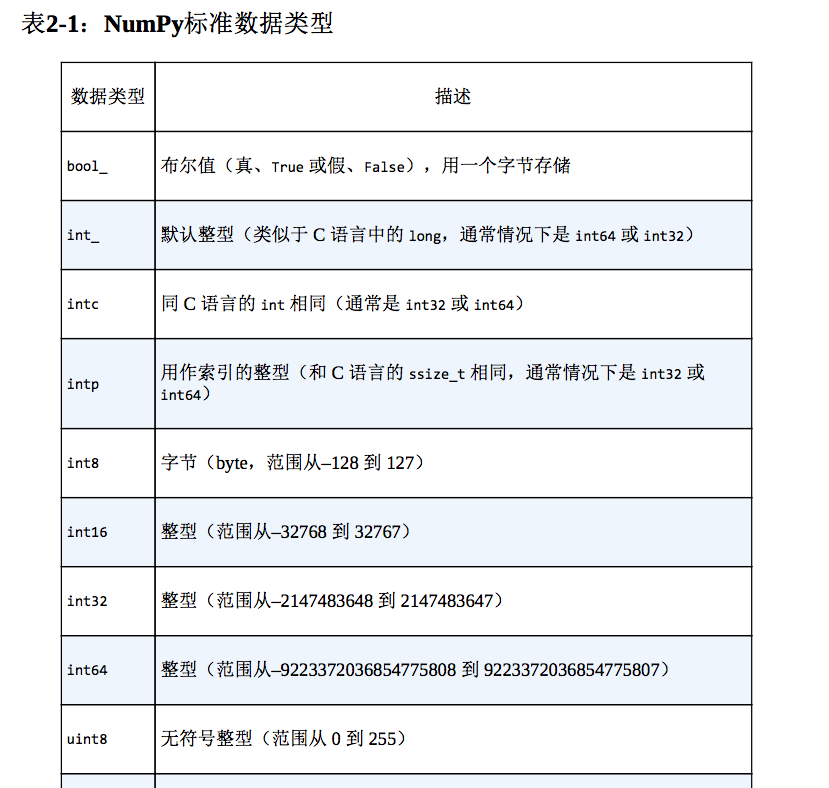
NumPy标准数据类型
NumPy数组包含同一类型的值,因此详细了解这些数据类型及其限制是非常重要的。因为NumPy是在C语言的基础上开发的,所以c的用户会比较熟悉这些数据类型。
当构建一个数组时,你可以用一个字符串参数来指定数据类型。
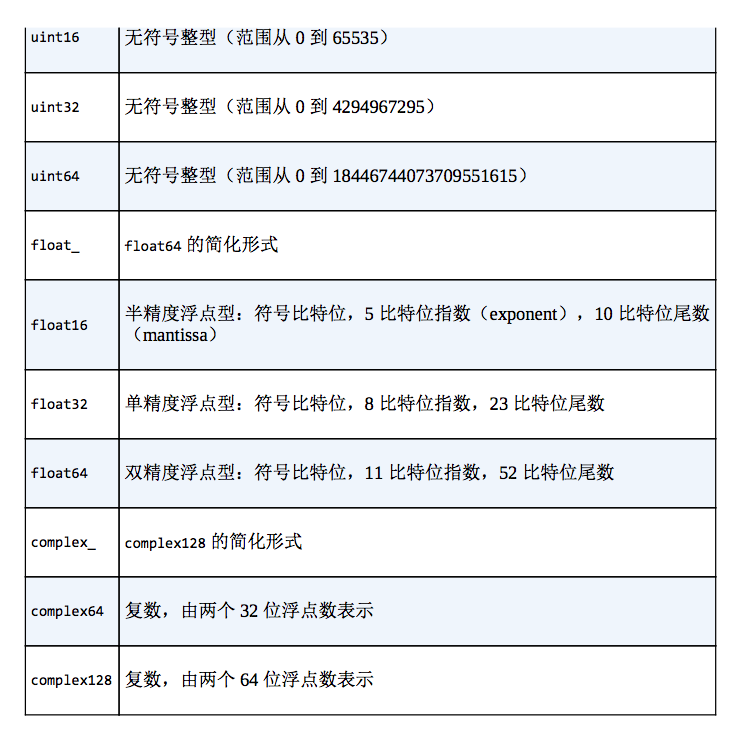
还可以进行更高级的数据类型指定,例如指定高位字节数或低位字节数。
NumPy数组基础
python中的数据操作几乎等同于NumPy数组操作,甚至新出现的Pandas工具也是构建在NumPy数组基础上的。
NumPy数组的属性
我们将用NumPy的随机数生成器设置一组种子值,以确保每次程序执行时都可以生成同样的随机数组。
每个数组有nidm(维度)、shape(数组每个维度的大小)和size(数组的大小)属性:
另一个有用的属性时dtype,它是数组的数据类型。其他的属性包括每个数组元素字节的大小itemsize,以及表示数组总字节大小的属性nbytes。可以认为nbytes跟itemsize和size的乘积大小相等。
数组索引:获取单个元素
NumPy中可以通过中括号指定索引获取第i个值(从0开始计数),为了获取数组的末尾索引,可以用负值索引,在多维数组中,可以用逗号分隔的索引元组获取元素。也可以用以上索引方式修改元素值。注意:和Python列表不同,NumPy数组是固定类型的。这意味着当试图将一个浮点值插入一个整型数组时,浮点值会被截断成整型,并且是自动完成的。
数组切片:获取子数组
可以用切片(slice)符号获取子数组,切片符号用冒号(:)表示。


多维子数组
多维切片也采用同样的方式处理,用冒号分隔。
子数组维度也可以同时被逆序。
获取数组的行和列
一种常见的需求是获取数组的单行和单列。你可以将索引与切片组合起来实现这个功能。用一个冒号(:)表示空切片。
在获取行时,出于语法的简介考虑,可以省略空的切片。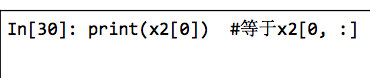
非副本视图的子数组
关于数组切片有一点很重要也非常有用,那就是数组切片返回的是数组数据的视图,而不是数值数据的副本。这一点也是 NumPy数组切片和 Python列表切片的不同之处:在 Python列表中,切片是值的副本。这种默认的处理方式实际上非常有用:它意味着在处理非常大的数据集时,可以获取或处理这些数据集的片段,而不用复制底层的数据缓存。
创建数组的副本
尽管数组视图有一些非常好的特性,但是在有些时候明确地复制数组里的数据或子数组也是非常有用的。可以简单地通过copy()方法实现。
如果修改这个子数组,原始的数值不会被改变。
数组的变形
数组变形最灵活的实现方式是通过reshape()函数来实现。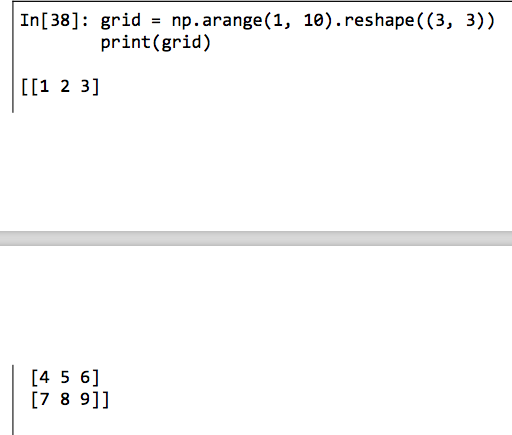
如果希望该方法可行,那么原始数组的大小必须和变形后数组的大小一致。如果满足条件reshape方法将会用到原始数组的一个非副本视图。但实际是,在非连续的数据缓存下,返回非副本视图往往不可能实现。
一个常见的变形模式是将一个一位数组转变为二维的行或列的矩阵。
数组拼接和分裂
数组的拼接
拼接或连接NumPy中的两个数组主要由np.concatenate、np.vstack和np.hstack例程实现。
也可以一次拼接两个以上数组。
np.concatentate也可以由于二维数组的拼接。
沿着固定维度处理数组时,使用np.vstack(垂直栈)和np.hstack(水平栈)函数会更简洁。
与之类似,np.dstack将沿着第三个维度拼接数组。
数组的分裂
分裂可以通过np.split、np.hsplit和np.vsplit函数来实现。可以转递一个索引列表作为参数,索引列表记录的是分裂点位置。
n分裂点会得到n+1个子数组。np.hsplit和np.vsplit的用法也类似。
同样,np.dspliy将数组沿着第三个维度分裂。
NumPy数组的计算:通用函数
缓慢的循环
Python的默认实现(被称作 CPython)处理起某些操作时非常慢,一部分原因是该语言的动态性和解释性—数据类型灵活的特性决定了序列操作不能像C语言和 Fortran语言一样被编译成有效的机器码。目前,有一些项目试图解决 Python这一弱点,比较知名的包括:PyPy项目一个实时的 Python编译实现; Cython项目,将 Python代码转换成可编译的C代码;Nuba项目,将 Python代码的片段转换成快速的LLⅴM字节码。以上这些项目都各有其优势和劣势,但是比较保守地说,这些方法中还没有一种能达到或超过标准 CPython引擎的受欢迎程度。
Python的相对缓慢通常出现在很多小操作需要不断重复的时候,比如对数组的每个元素做循环操作时。处理结果所花费的时间是不合时宜的慢,处理瓶颈并不是运算本身,而是CPython在每次循环时必须做数据类型的检查和函数调度。在进行循环中每一轮的运算时,Python首先检查对象的类型,并且动态查找可以使用该数据类型的正确函数。如果我们在编译代码时进行这样的操作,那么就能在代码执行之前知晓类型的声明,结果的计算也会更加有效率。
通用函数介绍
NumPy为很多类型的操作提供了非常方便的、静态类型的、可编译程序的接口,也被称作向量操作。你可以通过简单地对数组执行操作来实现,这里对数组的操作将会被用于数组中的每一个元素。这种向量方法被用于将循环推送至 NumPy之下的编译层,这样会取得更快的执行效率。如果计算一个较大数组的运行时间,可以看到它的时间比Python循环花费的时间更短。
探索NumPy的通用函数
通用函数有两种存在形式:一元通用函数( unary func)对单个输入操作,二元通用函数( binary ufunc)对两个输入操作。
数组的运算
NumPy通用函数的使用方式非常自然,因为它用到了 Python原生的算术运算符,标准的加、减、乘、除都可以使用,还有逻辑非,指数运算符和模运算符的一元通用函数。可以任意将这些算术运算符组合使用,当然得考虑这些运算符的优先级。所有这些算术运算符都是NumPy内置函数的简单封装器,例如+运算符就是一个add函数的封装器。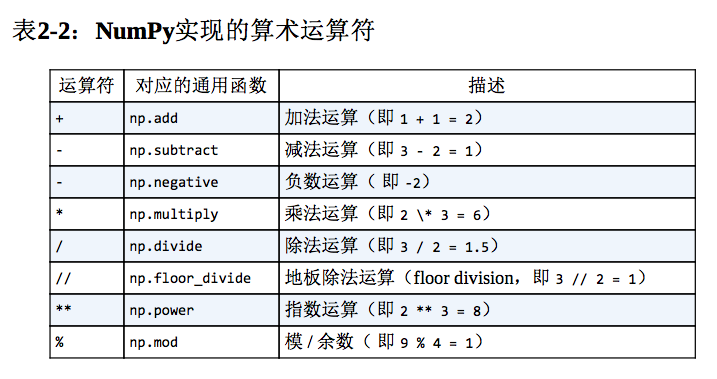
绝对值
正如 NumPy能理解 Python内置的运算操作, NumPy也可以理解Python内置的绝对值函数。对应的 NumPy通用函数是 np. absolute,该函数也可以用别名np. abs来访问。
三角函数
NumPy提供了大量好用的通用函数,其中对于数据科学家最有用的就是三角函数。
np.sin() np.cos() np.tan()
逆三角函数同样可以使用。
np.arcsin() np.arccos() np.arctan()
指数和对数
np.log np.exp
专用的通用函数
除了以上介绍到的, NumPy还提供了很多通用函数,包括双曲三角函数、比特位运算、比较运算符、弧度转化为角度的运算、取整和求余运算,等等。浏览 NumPy的文档将会揭示很多有趣的功能。还有一个更加专用,也更加晦涩的通用函数优异来源是子模块scipy. special。如果你希望对你的数据进行一些更晦涩的数学计算, scipy. special可能包含了你需要的计算函数。
NumPy和 scIpy. specia1中提供了大量的通用函数,这些包的文档在网上就可以查到,搜索“ gamma function python”即可。
高级的通用函数特性
指定输出

对于较大的数组,通过慎重使用out参数能有效节约内存。
聚合
二元通用函数有些非常有趣的聚合功能,这些聚合可以直接在对象上计算。例如,如果我们希望用一个特定的运算 reduce一个数组,那么可以用任何通用函数的 reduce方法。一个 reduce方法会对给定的元素和操作重复执行,直至得到单个的结果。如果需要存储每次计算的中间结果,可以使用accumulate。

请注意,在一些特殊情况中, NumPy提供了专用的函数(np.sum、np.prod、np. cumsum、np. cumprod),它们也可以实现以上 reduce的功能。
外积
最后,任何通用函数都可以用 outer方法获得两个不同输入数组所有元素对的函数运算结果。这意味着你可以用一行代码实现一个乘法表。
通用函数:更多的信息
有关通用函数的更多信息(包括可用的通用函数的完整列表)可以在NumPy和SciPy文档的网站找到。
聚合:最小值、最大值和其他值
当面对大量的数据时,第一个步骤通常都是计算相关数据的概括统计值。最常用的概括统计值可能是均值和标准差,这两个值能让你分别概括出数据集中的“经典”值,但是其他一些形式的聚合也是非常有用的(如求和、乘积、中位数、最小值和最大值、分位数,等等)。
数组值求和
Sum函数和np.sum函数并不等同,这有时会导致混淆。尤其是它们各自的可选参数都有不同的含义,np.sum函数是知道数组的维度的。sum是python求和,当然np.sum更快。
最小值和最大值
Python也有内置的min函数和max函数,分别被用于获取给定数组的最小值和最大值,NumPy对应的函数也有类似的语法,并且也执行得更快。
多维度聚合
一种常用的聚合操作时沿着一行或一列聚合。默认情况下,每一个NumPy聚合函数将会返回对整个数组的聚合结果,聚合函数还有一个参数,用于指定沿着哪个轴的方向进行聚合。axis关键字指定的是数组将会被折叠的维度,而不是将要返回的维度。因此指定axis=0意味着第一个轴将要被折叠。对于二维数组,这意味着每一列的值都将被聚合。
其他聚合函数
大多数的聚合都有对NaN值的安全处理策略,即计算时忽略所有的缺失值。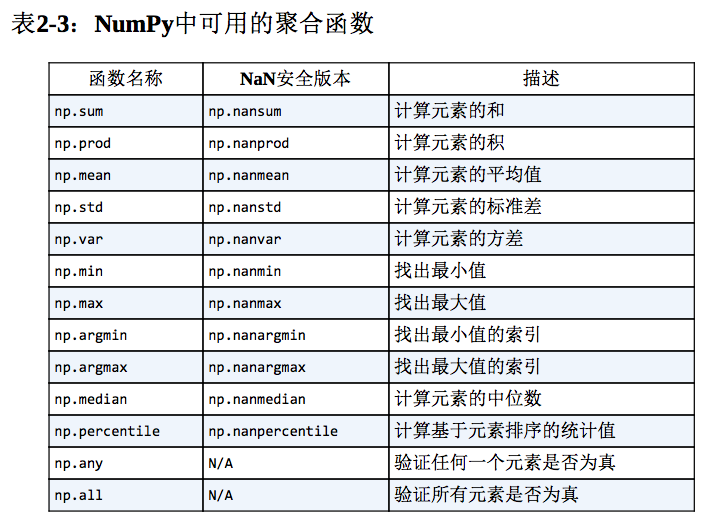
数组的计算:广播
另外一种向量化操作的方法是利用 NumPy的广播功能。广播可以简单理解为用于不同大小数组的二进制通用函数(加、减、乘等)的一组规则。
广播的介绍
对于同样大小的数组,二进制操作是对相应元素逐个计算。
广播允许这些二进制操作可以用于不同大小的数组,例如可以将一个标量和一个数组相加。
我们也可以将这个原理扩展到更高维度,将一个一位数组和一个二维数组相加。
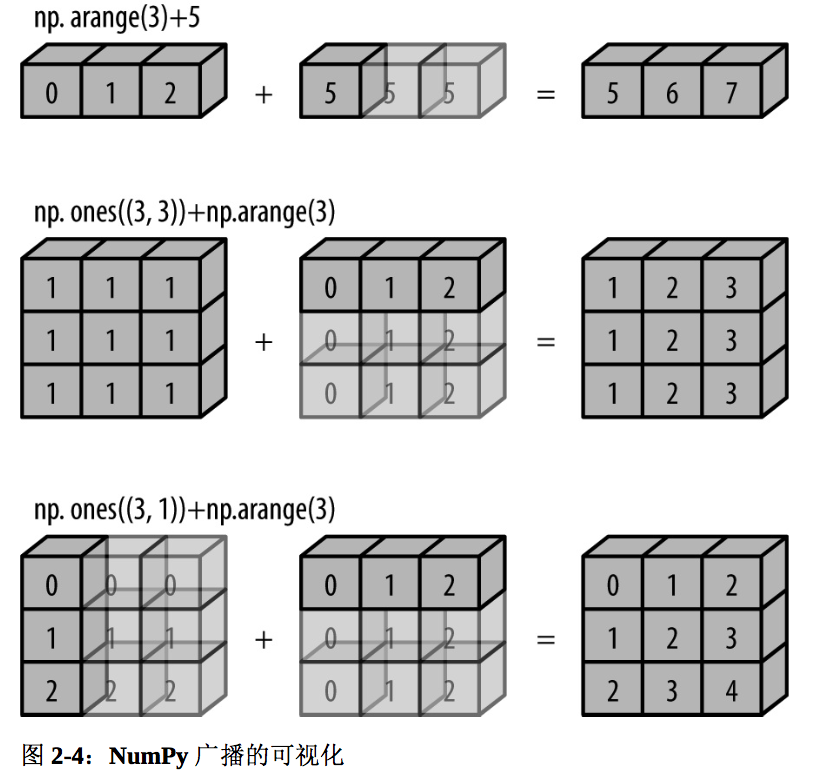
浅色的盒子表示广播的值。需要注意的是,这个额外的内存并没有在实际操作中进行分配,但是这样的想象方式更方便我们从概念上理解。
广播的规则

比较、掩码和布尔逻辑
这一节将会介绍如何用布尔掩码来查看和操作 NumPy数组中的值。当你想基于某些准则来抽取、修改、计数或对一个数组中的值进行其他操作时,掩码就可以派上用场了。例如你可能希望统计数组中有多少值大于某一个给定值,或者删除所有超出某些门限值的异常点。在NumPy中,布尔掩码通常是完成这类任务的最高效方式。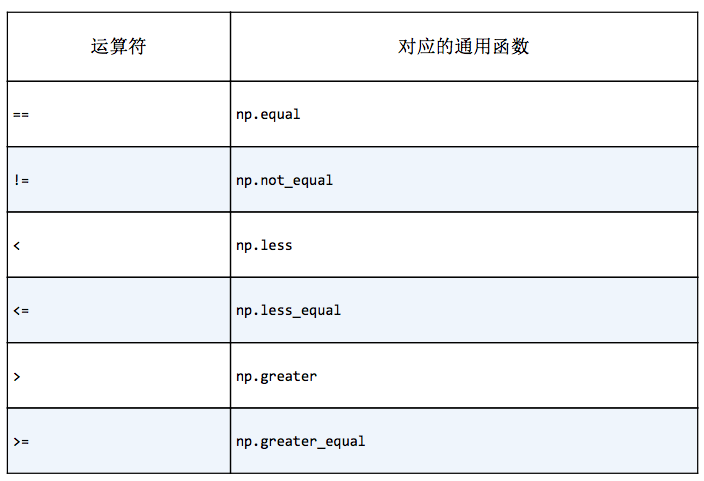
操作布尔数组
统计记录的个数
如果需要统计布尔数组中True记录的个数,可以使用np. count_nonzero函数。
如要快速检查任意或者所有的值是否为True,可以用np.any()或np.all()。
布尔运算值
同标准的算术运算符一样,NumPy用通用函数重载了这些逻辑运算符,这样可以实现数组的逐位运算(通常是布尔运算)。

将布尔数组作为掩码

花哨的索引
花哨的索引和前面那些简单的索引非常类似,但是传递的是索引数组,而不是单个标量。花哨的索引让我们能够快速获得并修改复杂得数组值的字数据集。
探索花哨的索引
花哨的索引在概念上非常简单,它意味着传递一个索引数组来一次性获得多个数组元素。

花哨的索引也对多个维度适用。
组合索引
花哨的索引可以和其他索引方案结合起来形成更强大的索引操作。
更可以将花哨的索引和掩码组合使用。
数组的排序
NumPy中的快速排序:np.sort和np.argsort
尽管Python有内置的sort和sorted函数可以对列表进行排序,但是效率并不高,NumPy的np.sort函数实际上效率更高。默认情况下,np.sort的排序算法是快速排序,其算法复杂度O[NlogN],另外也可以选择归并排序和堆排序。对于大多数应用场景,默认的快速排序已经足够高效了。

NumPy排序算法的一个有用功能是通过axis参数,沿着多维数组的行或列进行排序。
这种处理方式是将行或列当做独立的数组,任何行或列的值之间的关系将会丢失。
部分排序:分隔
有时候我们不希望对整个数组进行排序,仅仅希望找到数组中第K小的值,NumPy的np.partition函数提供了该功能,最左边是第K小的值,往右是任意顺序的其他值。
与排序类似,也可以沿着多维数组任意的轴进行分割。
正如np.argsort函数计算的是排序的索引值,也有一个np.argpartition函数计算的是分隔的索引值。
结构化数据:NumPy的结构化数组

这里U1表示“长度不超过10的 Unicode字符串”,i4表示“4字节(即32比特)整型”,f8表示“8字节(即64比特)浮点型”。
现在生成了一个空的数组容器,可以将列表数据放入数组中。
正如我们希望的,所有的数据被安排在一个内存块中。


更高级的复合类型
NumPy中也可以定义更高级的复合数据类型。例如,你可以创建一种类型,其中每个元素都包含一个数组或矩阵。我们会创建一个数据类型,该数据类型用mat组件包含一个3×3的浮点矩阵。
现在X数组的每个元素都包含一个id和一个3×3的矩阵。为什么我们宁愿用这种方法存储数据,也不用简单的多维数组,或者 Python字典呢?原因是 NumPy的 dtype直接映射到C结构的定义,因此包含数组内容的缓存可以直接在C程序中使用。如果你想写一个 Python接口与一个遗留的C语言或 Fortran库交互,从而操作结构化数据,你将会发现结构化数组非常有用!
记录数组:结构化数组的扭转
NumPy还提供了np.recarray类。它和前面介绍的结构化数组几乎相同,但是它有一个独特的特征:域可以像属性一样获取,而不是像字典的键那样获取。