中文分词方法的演变
对于西方拼音语言来说,词之间有明显的分界符,统计和使用语言模型非常直接。而对于中日韩泰等语言,词之间没有明确的分界符。
最容易想到的分词方法,也是最简单的办法,就是查字典。“查字典”的办法,其实就是把一个句子从左向右扫描一遍,遇到字典里有的词就标识出来,遇到复合词(比如“上海大学”)就找最长的词匹配,遇到不认识的字串就分割成单字词,于是简单的分词就完成了。
这个最简单的方法可以解决七八成以上的分词问题,遇到稍微复杂一点的问题就无能为力了。这种方法的一个明显不足时当遇到有二义性的分割时无能为力,另外并非所有的最长匹配都是一定正确的。
利用统计语言模型分词的方法,可以用几个数学公式简单概括如下:假定一个句子S可以有几种分词方法,为了简单起见,假定有以下三种:
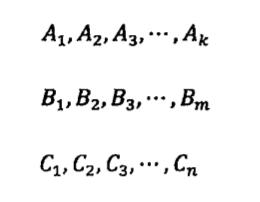
其中,A1,A2…B1,B2…,C1,C2…等等都是汉语的词,那么最好的一种分词方法应该保证分完词后这个句子出现的概率最大。
当然,这里面有一个实现的技巧。如果穷举所有可能的分词方法并计算出每种可能性下句子的概率,那么计算量是相当大的。因此,可以把它看成是一个动态规划( Dynamic Programming)的问题,并利用维特比( Viterbi)算法快速地找到最佳分词。(我们在后面的章节会介绍该算法。)
一般来讲,根据不同应用,汉语分词的颗粒度大小应该不同。
中文分词方法可以帮助判别英语单词的边界。因为手写英文字符时已经不能明显的区分边界了。
最后,需要指出的是任何方法都有它的局限性,虽然利用统计语言模型进行分词,可以取得比人工更好的结果,但是也不可能做到百分之百准确。因为统计语言模型很大程度上是依照“大众的想法”,或者“多数句子的用法”,而在特定情况下可能是错的。
工程上的细节
分词的一致性
如何衡量分词结果的对与错,好与坏看似容易,其实不是那么简单。说它看似容易,是因为只要对计算机分词的结果和人工分词的结果进行比较就可以了。说它不是那么简单,是因为不同的人对同一个句子可能有不同的分词方法。不同的人对词的切分看法上的差异性远比我们想象的要大得多。当统计语言模型被广泛应用后,不同的分词器产生的结果的差异要远远小于不同人之间看法的差异,这时简单依靠与人工分词的结果比较来衡量分词器的准确性就很难,甚至是毫无意义的了。中文分词现在是一个已经解决了的问题,提高的空间微乎其微了。只要采用统计语言模型,效果都差不到哪里去。
词的颗粒度和层次
人工分词产生不一致性的原因主要在于人们对词的颗粒度的认识问题。在这里不去强调谁的观点对,而是要指出在不同的应用中,会有一种颗粒度比另一种更好的情况。比如在机器翻译中,一般来讲,颗粒度大翻译效果好。比如“联想公司”作为一个整体,很容易找到它对应的英语翻译 Lenovo,如果分词时将它们分开,很有可能翻译失败。
虽然可以对不同的应用构造不同的分词器,但是这样做不仅非常浪费,而且也不必要。更好的方法是让一个分词器同时支持不同层次的词的切分。