高级特性
切片
取数组前3个元素,用一行代码就可以完成切片。
从索引0开始取,直到索引3为止,但不包括索引3。
如果第一个索引是0,还可以省略。
Python支持L[-1]取倒数第一个元素,那么它同样支持倒数切片。
后10个数,L[-10:]。前10个数,每两个取一个,L[:10:2]。甚至什么都不写,只写[:]就可以原样复制一个list。
tuple也是一种list,唯一区别是tuple不可变。因此,tuple也可以用切片操作,只是操作的结果仍是tuple。
字符串’xxx’也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串。
Python没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
迭代
当我们使用for循环时,只要作用于一个可迭代对象,for循环就可以正常运行,而我们不太关心该对象究竟是list还是其他数据类型。
通过collections模块的Iterable类型判断一个对象是可迭代对象。
Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身。
for循环里,同时引用了两个变量,在Python里是很常见的。
列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]可以用list(range(1, 11))。
列表生成式则可以用一行语句代替循环。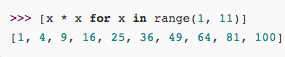
for循环后面还可以加上if判断。
还可以使用两层循环,还可以使用两层循环。
for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value。
生成器
创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
如果列表元素可以按照某种算法推算出来,可以在循环的过程中不断推算出后续的元素,就不必创建完整的list。Python中,这种一边循环一边计算的机制,称为生成器:generator。
把一个列表生成式的[]改成(),就创建了一个generator。
通过next()函数获得generator的下一个返回值。
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象。
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。
最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
调用该generator时,首先要生成一个generator对象,然后用next()函数不断获得下一个返回值。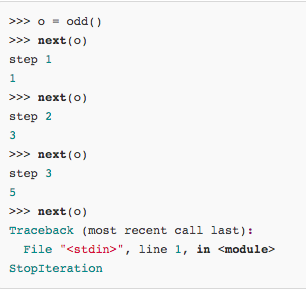
我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代。
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中。
迭代器
可以直接作用于for循环的对象统称为可迭代对象:Iterable。如集合数据类型,如list、tuple、dict、set、str等,generator,包括生成器和带yield的generator function。
可以使用isinstance()判断一个对象是否是Iterable对象。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象。
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数。
Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。所以list、dict、str等数据类型不是Iterator。
函数式编程
高阶函数
map/reduce
Python内建了map()和reduce()函数。
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
所以,map()作为高阶函数,事实上它把运算规则抽象了,能一眼看明白“把f(x)作用在list的每一个元素并把结果生成一个新的list。
reduce把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算。

假设Python没有提供int()函数,你完全可以自己写一个把字符串转化为整数的函数,而且只需要几行代码!
filter
Python内建的filter()函数用于过滤序列。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
sorted
排序算法
Python内置的sorted()函数就可以对list进行排序。
sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序。
key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。
从上述例子可以看出,高阶函数的抽象能力是非常强大的,而且,核心代码可以保持得非常简洁。
返回函数
函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
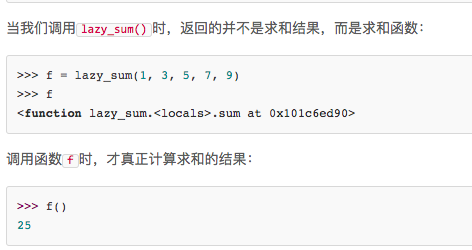
闭包
返回的函数并没有立刻执行,而是直到调用了f()才执行。
返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
匿名函数
匿名函数lambda x: x * x实际上就是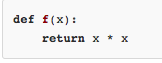
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数。
同样,也可以把匿名函数作为返回值返回,比如。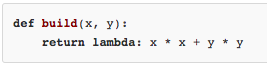
装饰器
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
函数对象有一个name属性,可以拿到函数的名字。
在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
本质上,decorator就是一个返回函数的高阶函数。
我们要定义一个能打印日志的decorator,可以定义如下。
我们要借助Python的@语法,把decorator置于函数的定义处。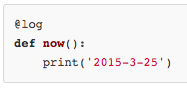
把@log放到now()函数的定义处,相当于执行了语句。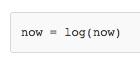
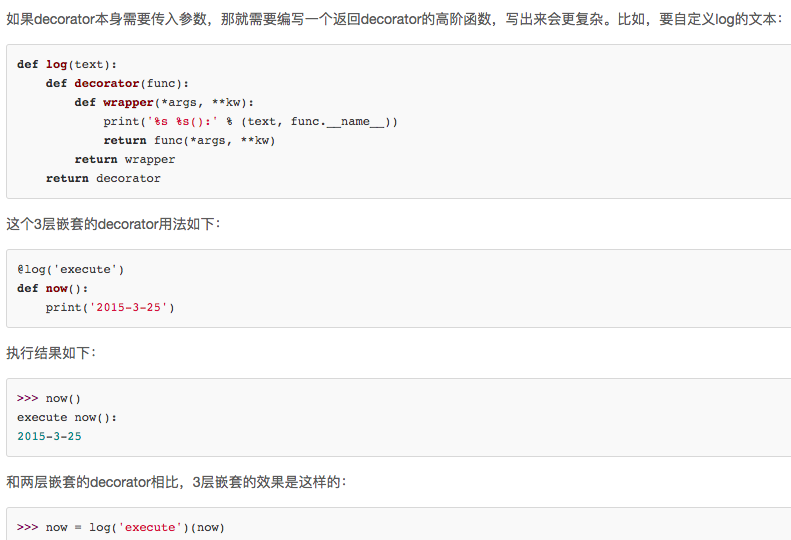
将原函数now传入log函数之中,返回wrapper函数,包含了原本的now功能以及加上了新的功能。将值赋予now。这样就完成了装饰。
偏函数
Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。要注意,这里的偏函数和数学意义上的偏函数不一样。
简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
模块
使用模块
Python本身就内置了很多非常有用的模块,只要安装完毕,这些模块就可以立刻使用。
作用域
在一个模块中,我们可能会定义很多函数和变量,但有的函数和变量我们希望给别人使用,有的函数和变量我们希望仅仅在模块内部使用。在Python中,是通过_前缀来实现的。
正常的函数和变量名是公开的(public),可以被直接引用,比如:abc,x123,PI等;
类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的__author__,__name__就是特殊变量,hello模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名;
类似_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;
之所以我们说,private函数和变量“不应该”被直接引用,而不是“不能”被直接引用,是因为Python并没有一种方法可以完全限制访问private函数或变量,但是,从编程习惯上不应该引用private函数或变量。
外部不需要引用的函数全部定义成private,只有外部需要引用的函数才定义为public,这也是一种非常有用的代码封装和抽象的方法。
安装第三方模块
在Python中,安装第三方模块,是通过包管理工具pip完成的。
注意:Mac或Linux上有可能并存Python 3.x和Python 2.x,因此对应的pip命令是pip3。
一般来说,第三方库都会在Python官方的pypi.python.org网站注册,要安装一个第三方库,必须先知道该库的名称,可以在官网或者pypi上搜索,比如Pillow的名称叫Pillow,因此,安装Pillow的命令就是。
安装常用模块
我们装上Anaconda,就相当于把数十个第三方模块自动安装好了,非常简单易用。
模块搜索路径
当我们试图加载一个模块时,Python会在指定的路径下搜索对应的.py文件,如果找不到,就会报错。
默认情况下,Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在sys模块的path变量中。
如果我们要添加自己的搜索目录,有两种方法
一是直接修改sys.path,添加要搜索的目录。
第二种方法是设置环境变量PYTHONPATH,该环境变量的内容会被自动添加到模块搜索路径中。设置方式与设置Path环境变量类似。注意只需要添加你自己的搜索路径,Python自己本身的搜索路径不受影响。