标量、向量、矩阵和张量
- 标量( scalar)一个标量就是一个单独的数,它不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。我们用斜体表示标量。标量通常被赋予小写的变量名称。当我们介绍标量时,会明确它们是哪种类型的数。比如,在定义实数标量时,我们可能会说“令s∈R表示一条线的斜率”;在定义自然数标量时,我们可能会说“令n∈N表示元素的数目”。
- 向量( vector):一个向量是一列数。这些数是有序排列的。通过次序中的索引,我们可以确定每个单独的数。通常我们赋予向量粗体的小写变量名称,比如x。向量中的元素可以通过带脚标的斜体表示。向量x的第一个元素是x1,第二个元素是x2,等等。我们也会注明存储在向量中的元素是什么类型的。如果每个元素都属于R,并且该向量有n个元素,那么该向量属于实数集R的n次笛卡尔乘积构成的集合,记为
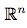
。当需要明确表示向量中的元素时,我们会将元素排列成一个方括号包围的纵列: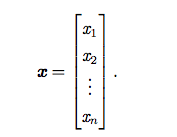
我们可以把向量看作空间中的点,每个元素是不同坐标轴上的坐标。有时我们需要索引向量中的一些元素。在这种情况下,我们定义一个包含这些元素索引的集合,然后将该集合写在脚标处。比如,指定x1,和,我们定义集合S={1,3,6},然后写作xs。我们用符号一表示集合的补集中的索引。比如x-1表示x中除x1外的所有元素,x-s表示x中除x1,x3,x6外所有元素构成的向量。
- 矩阵( matrix):矩阵是一个二维数组,其中的每一个元素被两个索引(而非一个)所确定。我们通常会赋予矩阵粗体的大写变量名称,比如A(斜体)。如果一个实数矩阵高度为m,宽度为n,那么我们说
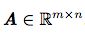
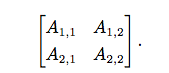
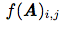
- 张量( tensor):在某些情况下,我们会讨论坐标超过两维的数组。一般地个数组中的元素分布在若干维坐标的规则网格中,我们称之为张量。我们使用字体A(不是斜体)来表示张量“A”。张量A中坐标为(i,j,k)的元素记作Ai,j,k。
- 转置( transpose)是矩阵的重要操作之一。矩阵的转置是以对角线为轴的镜像这条从左上角到右下角的对角线被称为主对角线( main diagonal)。我们将矩阵A的转置表示为AT,定义如下
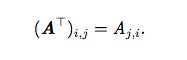
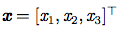
转置的运算性质
1 | 【】只是记法 |

在深度学习中,我们也使用一些不那么常规的符号。我们允许矩阵和向量相加,产生另一个矩阵:C=A+b,其中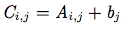
。换言之,向量b和矩阵A的每一行相加。这个简写方法使我们无需在加法操作前定义一个将向量b复制到每一行而生成的矩阵。这种隐式地复制向量b到很多位置的方式,被称为广播( broadcasting )。
矩阵和向量相乘


单位矩阵和逆矩阵


线性相关和生成子空间


1 | 还有一种看法是以列向量为新的参考系,看在参考系下要表示的向量的坐标。 |

不等式n≥m仅是方程对每一点都有解的必要条件。这不是一个充分条件。

1
奇异值行列式为0
范数
有时我们需要衡量一个向量的大小。在机器学习中,我们经常使用被称为范数(norm)的函数衡量向量大小。形式上,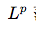
范数定义如下: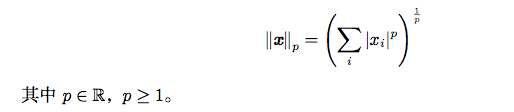
范数(包括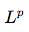
范数)是将向量映射到非负值的函数。直观上来说,向量x的范数衡量从原点到点x的距离。更严格地说,范数是满足下列性质的任意函数:
当p=2时,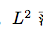
范数被称为欧几里得范数( Euclidean norm)。它表示从原点出发到向量c确定的点的欧几里得距离。L2范数在机器学习中出现地十分频繁,经常简化表示为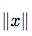
,略去了下标2。平方L2范数也经常用来衡量向量的大小,可以简单地通过点积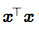
计算。


另外一个经常在机器学习中出现的范数是L∞范数,也被称为最大范数(max norm)这个范数表示向量中具有最大幅值的元素的绝对值: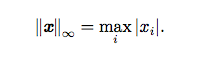

1 | 弗罗贝尼乌斯范数 |

特殊类型的矩阵和向量
对角矩阵

对称

单位向量

正交矩阵

特征分解
特征分解( eigendecomposition)是使用最广的矩阵分解之一,即我们将矩阵分解成一组特征向量和特征值。




1
矩阵A乘以x表示,对向量x进行一次转换(旋转或拉伸)(是一种线性转换),而该转换的效果为常数c乘以向量x(即只进行拉伸)。
奇异值分解
我们探讨了如何将矩阵分解成特征向量和特征值。还有另一种分解矩阵的方法,被称为奇异值分解( singular value decomposition,SVD),将矩阵分解为奇异向量( singular vector)和奇异值( singular value)。通过奇异值分解,我们会得到一些与特征分解相同类型的信息。然而,奇异值分解有更广泛的应用。每个实数矩阵都有一个奇异值分解,但不一定都有特征分解。例如,非方阵的矩阵没有特征分解,这时我们只能使用奇异值分解。

Moore-Penrose伪逆


迹运算
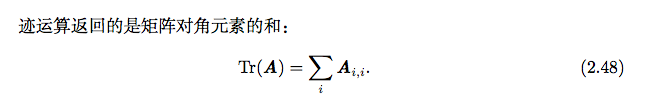

另一个有用的事实是标量在迹运算后仍然是它自己:a=Tr(a)。
行列式
行列式,记作det(A),是一个将方阵A映射到实数的函数。行列式等于矩阵特征值的乘积。行列式的绝对值可以用来衡量矩阵参与矩阵乘法后空间扩大或者缩了多少。如果行列式是0,那么空间至少沿着某一维完全收缩了,使其失去了所有的体积。如果行列式是1,那么这个转换保持空间体积不变。
实例:主成分分析
主成分分析( principal components analysis,PCA)是一个简单的机器学习算法,可以通过基础的线性代数知识推导。