松本行弘的程序世界 14 函数式编程
新范型–函数式编程
函数式编程是全部使用函数来编写程序代码的编程方法。这是可以与一般的结构化编程及面向对象编程相提并论的编程方法。
以函数为中心的函数式编程具有特征:
- 函数本身也作为数据来处理(第一级函数)
- 以函数为参数的高阶函数
- 参数相同即可保证结果相同的引用透明性。
- 为实现引用透明性,禁止产生副作用的处理。
函数式编程的最大优点在于,程序可以按照数学的形式以及声明的形式来编写。
结构式编程是在改变变量值的同时进行计算,所以一直注意着,这个变量的值是什么,并据此来预想计算过程。
采用函数式编程方式并不改变变量的值。并不包含状态或者动作等信息,仅仅是对想要做什么加以描述,这样不容易出错。
这种不是描述动作而是描述性质的编程方式称为声明式编程。声明式描述是函数式编程的一大优点。
具有多种函数式性质的Lisp
之前,Lisp被认为是函数式编程的代表。Lisp具备函数式语言的很多性质。
Lisp最大的特征是S式记法。S式是括号很多的Lisp的记法。S式无与伦比的优点是它彻底的统一性。对Lisp而言,不管什么都可以同一成单一形式。
第二个重要之处在于链这种数据结构。Lisp语言本名是List Processor(链表处理器),从侧面说明了链的重要性。链是一种构成树结构数据的通用数据结构,构成数据结构的节点分别包含两个引用。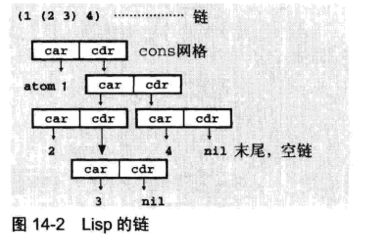
总之,Lisp具备了函数编程语言的基本特征。但是Lisp不直接支持多数纯粹的函数式编程语言所拥有的副作用如回避以及延迟计算等功能。对变量的赋值没有任何限制。且编程风格为很多很多括号。比较难适应。
近年来,由于像Haskell这样的彻底的函数式编程语言的兴起,Lisp作为函数式编程语言在人们心中的印象越来越淡薄。
彻底的函数式编程语言Haskell
Haskell可以说是纯粹的函数式编程语言。
Haskell语言特征:
- 没有副作用
- 高阶函数
- 函数部分应用
- 延迟计算(非正式)
- 静态多态类型系统
- 型推论
- 链内包表达式
- 用对齐来表示块
没有副作用
Haskell程序基本没有副作用,不但不能改变变量的值,就连链的元素也是不能改变的。因此,只要参数不变,函数的返回值也就总是一样的。相同输入总能返回相同结果,这种可重复性对测试程序非常有利。这种重复性也称为引用透明性。
高阶函数
Haskell高阶函数把函数本身作为数据来处理。比如,Haskell中没有循环控制结构,循环都是用递归调用或者高阶函数来实现的。
延迟计算:不必要的处理就不做
必要时才进行处理。
灵活的“静态多态性”类型系统
与没有类型的Ruby不同,Haskell是在编译时确定所有变量类型的静态类型语言。但实际上Haskell程序基本上没有必要给出变量的类型。这是因为聪明的Haskell语言处理系统会推测变量的类型。
Haskell利用多态性的类型系统和系统推测,在维持着接近于duck typing灵活性的同时,也使编译时的完全类型检查成为可能。
近代函数式语言之父OCaml
OCaml也是具有代表性的函数式编程语言之一。它比Haskell还古老,说它是近代函数式语言之父也毫不为过。
与Haskell相比,OCaml具有如下不同:
- 没有副作用
- 没有延迟计算
- 具有强力的模块系统
虽然不像Haskell那样自然地做到延迟计算,但换来的好处是,程序内容与实际处理关系接近,使人容易理解程序的执行过程。
强于并行计算的Erlang
作为函数式编程语言,二郎的特点
- 受Prolog影响
- 专用于并行计算
用Ruby进行函数式编程
Ruby中有几个能进行函数式编程的工具
Proc对象(lambda)
Ruby中唯一与函数直接对应的是Proc对象。
程序块
以程序块为参数的方法等价于函数型语言的高阶函数。灵活运用以程序块为参数的方法,就可以实现函数式编程的高阶函数的技巧。
枚举器
Ruby中没有延迟计算,但用枚举器对数组和列表进行循环,可以实现类似于延迟计算的处理。
避免副作用
所谓避免副作用,就是对生成的对象,尽量少去改变其状态。
用枚举器来实现延迟计算
从Ruby1.8.7开始,很多以块为参数的方法在参数不是块的时候,就会返回枚举器。
枚举器就是把循环用对象来表达的一种方法。
使用这样的枚举器可以实现与Haskell类似的延迟计算。
自动生成代码
在商业中利用Ruby
使用Ruby自动生成代码
编程中的代码重复是非常恶劣的。发现了代码重复,就应该考虑在合理的代价范围内避免代码重复的方法。
消除重复代码
为了在构建程序的时候,自动生成省略部分,我们只需要定义make的规则、在构建程序的过程中调用代码生成工具。
代码生成的应用
数据库访问
从数据结构定义自动生成数据库的访问例程(包括SQL)。
用户接口
大多数依赖于数据库的Web应用程序,常常需要对表的各项目进行增删改查操作。
单元测试
代码生成对单元测试也很有效果。只要有数据和测试条件,就可以开始单元测试。
客户界面
文档化
代码生成也适合与文档化。对于自动生成的类,由人工记入档案是纯粹的浪费。按照JavaDoc的形式,在生成代码的程序里写好相应的文档,应该是个聪明的办法。
代码生成的效果
代码生成有如下好处:
- 改进质量。
- 确保一致性
- 集中知识。
- 增加用于设计的时间。
- 独立于程序实现的设计判断
编写代码生成器
对代码生成最有帮助的工具要数eRuby。Ruby本身也拥有优越的文本处理功能。使用eRuby以比较自然地形式编写模板的同时,还可以灵活运用Ruby的处理能力。
也可以使用XML
幸运的是,Ruby拥有解释XML的标准库REXML。REXML提供操作XML的功能。
在EJB中使用代码生成
1 | EJB (Enterprise JavaBean)是J2EE(javaEE)的一部分 |
内存管理与垃圾收集
垃圾收集(GC)是一种管理程序使用的内存区域的方法。使用具有垃圾收集功能的编程语言或处理程序的话,程序中不需要编写内存管理的代码,即不用编写代码来释放使用过的内存区域。
内存管理的困难
在垃圾收集普及之前,内存区域的取得和释放完全是程序员的责任。随着程序的执行,会使用一些内存区域作为作业区。为记忆对象、字符串和数组等个别信息,都需要使用内存区域。没有垃圾收集的语言一般都提供有API,利用这些API,可以再需要时向操作系统申请并取得内存,使用过之后再把内存区域返回给操作系统。
悬挂指针
如果把还在使用中的内存区域错误调用free予以释放的话,就会发生悬挂指针的现象。程序再去访问该区域时就可能会出错。在引用该区域内容时,多数场合会读取到被破坏的数据,或是在更新该领域数据的时候,会置换成预想之外的数据。
内存泄漏
另一方面,如果忘记了把申请的内存区域返还给操作系统的话,就会发生内存泄漏。这时候因为使用过的内存区域越来越多,程序占有的内存就会逐渐增加。特别是长时间启动,连续提供服务的常驻内存型程序,容易发生内存泄漏,导致系统停止等重大问题。
二重释放
对已经释放过的内存区域再次调用free的情况也时有发生。这称为二重释放。这会带来malloc和free内部使用的数据区域不一致的问题。
内存泄漏问题只有在内存占用量超过预想的时候才会显露,而悬挂指针问题不会发生在释放使用内存的时刻,而是要到访问释放过的内存区域才会出现。程序员往往会在看起来完全没有问题的地方突然遭遇意想不到的错误。
垃圾收集亮相之前
应该管理的内存区域越来越多,内存释放时刻的管理也就越来越难,这是产生内存问题的原因。
关于垃圾收集,有以下这些先入为主的观念。
垃圾收集慢
有研究表明,在某些条件下,垃圾收集比手工管理内存还更快。
垃圾收集可靠性低
在Java之后诞生的编程语言,不管是否受到Lisp的影响,几乎都毫无例外的拥有垃圾收集的功能。垃圾收集从诞生之日起,经历了40多年的发展,终于成为大家认可的一项特性了。
评价垃圾收集的两个指标
假如存在无线内存的计算机的话,就没有必要进行垃圾收集。
垃圾收集的性能可以由两个指标来测定:
吞吐量
吞吐量是垃圾收集处理在程序全部执行时间中所占的比例。比例越小越好,比例大的话,程序整体的性能就会低下。
暂停时间
暂停时间是一次垃圾收集处理所中断的时间。暂停时间过长的话,处理的中断时间就会变得很显眼,程序反应就会变慢。
垃圾收集每次所花的时间会因垃圾收集执行时对象的总数而变化,暂停时间有两种,一是把垃圾收集时间求平均值得到平均暂停时间,二是程序执行中最长的垃圾收集时间所代表的最大暂停时间。
那些实时性要求高的程序,就很重视最大暂停时间。像批处理这样非对话的处理强调吞吐量要高,而重视反应速度的嵌入式或者GUI程序就强调暂停时间要短。
Java运行环境中实现由多种垃圾收集算法,可以根据程序的性质来切换合适的垃圾收集算法。
垃圾收集算法
基本上是以下4类,还有几种变形:
- 引用计数方式
- 标记和扫除方式
- 标记和紧缩方式
- 复制方式
引用计数方式
引用计数方式在垃圾收集算法中具有最简单最容易实现的特征。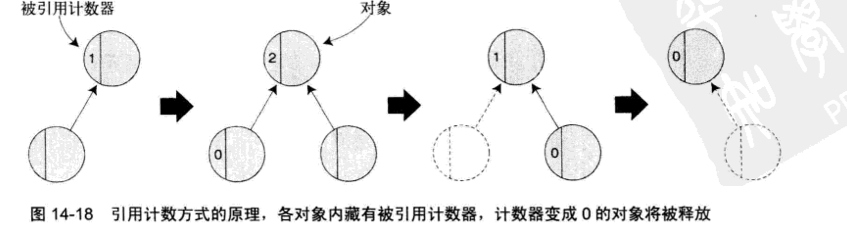
引用计数器最大的优点就是容易实现。这种方式得到广泛的使用。暂停时间短也是它的优点。
最大的缺点是不能释放有循环引用关系的对象群。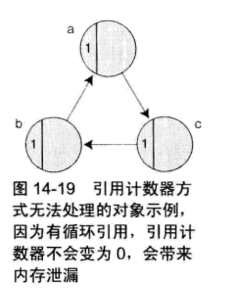
与生俱来的缺点,因为在引用增减的时候有必要同时正确维护引用计数器的增减,忘了这一点就会带来悬挂指针或内存泄露问题。
最后一个缺点是,引用计数器的管理与并行处理不相容。如果多个进程同时增减一个引用计数器的话,就会发生引用计数器的值不一致的现象。为避免这一个问题,需要在操作引用计数器的时候进行排他处理,但在频繁发生引用操作的同时进行排他处理的话,会带来巨大的时间开销。
总之,这种原理简单实现也简单的引用计数器方式,缺点很多,最近已经不怎么用了。
采用引用计数器方式的主要语言处理系统有Perl和Python。为了回避循环引用的问题,它们都组合了其他垃圾收集方式。这些语言基本上以引用计数器方式来进行垃圾收集,只有在极个别的情况下,才通过别的垃圾收集算法来处理引用计数器不能回收的对象。
标记和扫除方式
标记和扫除方式也是古老的垃圾收集算法。
标记和扫除方式从有可能成为对象引用元的变数(根)开始,给被引用的对象加上标记,表明其“活着”。然后再给标记对象所引用的对象还有其再引用的对象,也都递归地加上引用标记。
这样从根开始不管是直接还是间接,只要把所有引用的对象都加上标记的话,那么没有标记的对象就是没有被引用的,也就是“已经死了”。然后在所有的对象中找出没有标记的对象,把它们作为垃圾扫除出去。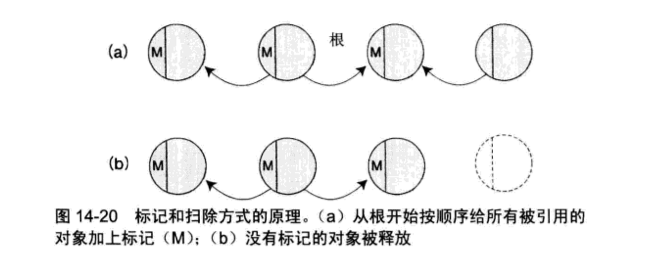
此法虽然古老,但是非常优秀,现在也还被多种处理系统所采用。
但是当对象数目较多时,性能容易恶化。在标记的时候要访问生存的所有对象,在回收时按顺序访问所有的对象,找出”已经死了“的对象。在寻找垃圾和扫除过程中,基本不能进行其他处理,垃圾收集时间长的话,会影响到本来的处理工作。
标记和紧缩方式
标记和紧缩方式是标记和扫除的变形。标记处理是一样的,后阶段有所不同。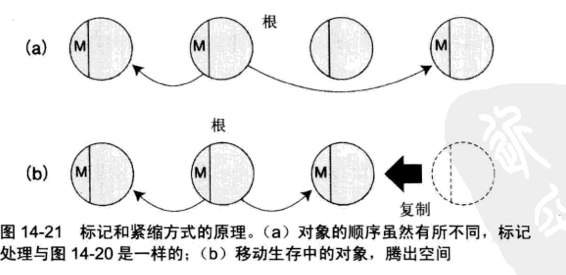
标记和紧缩方式最大的特征也是他的优越之处,是把空间集中起来(紧缩)。紧缩的结果是把没有释放而活下来的对象都集中到一个地方。这样,内存访问就集中到一个局部区域,这可以提高缓存功能的效率。对象的分配也只是把指针移动一下就完成了,降低了对象分配的开销。
缺点是,把生存着的对象全部复制的紧缩开销,容易比标记和扫除方式中执行的开销还要大。因为对象被移动位置了。
一部分Lisp处理系统采用的是标记和紧缩方式,Java处理系统(作为多个垃圾收集算法中的一个)也有标记和紧缩方式。
复制方式
像标记和扫除方式、标记和紧缩方式这样“标记之后释放死了的对象”的算法,标记时间与活着的对象数成比例,扫除时间与总对象数成比例。所以在分配有很多的对象,其中几乎所有对象都要被释放的场合,扫除的开销会变高,在性能方面很不利。
复制方式与标记和扫除方式一样,从根开始扫描所有的对象,但他不仅仅是加标记,还执行复制。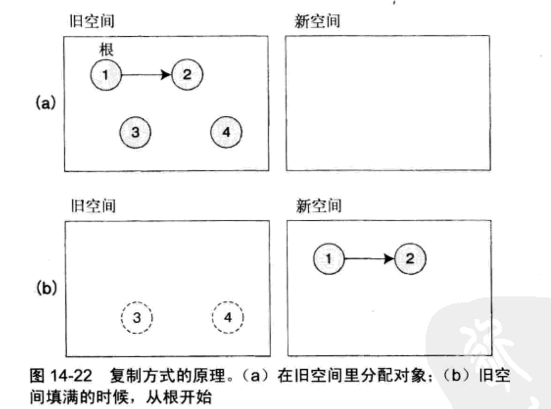
复制方式把内存空间分成旧空间和新空间两大块,总是在旧空间中分配对象。旧空间爆满时,从根开始扫描对象,把对象复制到新空间。这时,复制后的引用也要随之更新。
递归的执行从旧空间到新空间的复制,结束时就会把所有活着的对象都移动到新空间。不再被引用的对象都遗留到旧空间,旧空间就可以整个弃之不用,就避免了扫除的开销,从此再把新空间作为旧空间再进行同样的处理。
最大的优点是,垃圾回收的开销只和活着的对象数成比例。对象分配的开销也低。还有“局部性”的优点。复制方式按顺序把引用的对象复制到新空间,关系近的对象会被分配到相近的内存空间,称为局部性。关系近的对象被访问的可能性也高。计算机因为有缓存,内存空间相接近的访问可能具有较好的性能,局部性高的程序具有提高性能的优势。
缺点:复制方式要复制所有活着的对象,几乎具有和标记和紧缩方式一样的缺点。
多种多样的垃圾收集算法
把基本算法组合起来的技术,几个具有代表性的:
- 分代垃圾收集
- 保守垃圾收集
- 增量垃圾收集
- 并行垃圾收集
- 位图标志
这些技术的组合也是有可能的。
分代垃圾收集
分代垃圾收集的基本思想是利用程序和对象的性质。一般程序都有这样一个性质,几乎所有的对象都在比较短的时间里变成垃圾,存活时间超过一定程度的对象总是拥有更长的寿命。
因为这一性质,就可以重点对分配之后的年轻对象进行扫描,这样就不用扫描全部对象就可能高效率地回收垃圾。
分代垃圾收集把对象的内存空间分成两个,新代和旧代,也有分成3个的。
只扫描新代区域的回收称为轻垃圾收集,但没有检查旧代区域对新代的引用,被引用的对象可能误判死亡,就会带来内存问题。
解决这一问题的方法是,监视对象的更新。在旧代区域引用新代区域的同时,就把这一引用的记录例程以及对象的更新场所全都记录下来,这个检查例程叫做写屏障,记录旧代区域对新代区域的引用叫记录集。
以所有区域对象的垃圾收集称为全垃圾收集或重垃圾收集。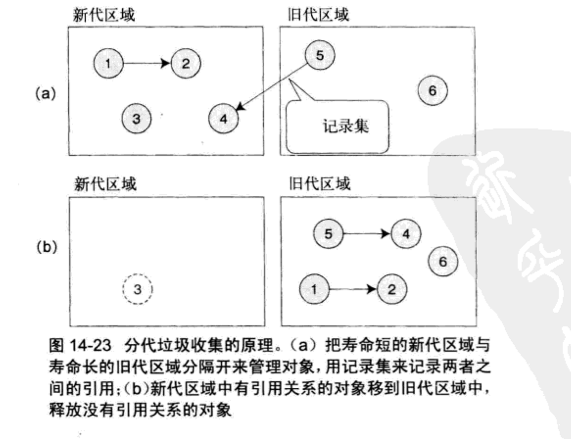
分代垃圾收集减少了扫描对象的个数,有缩短平均暂停时间的效果。但是,因为要执行全垃圾收集,最大暂停时间不会得到明显的改善。
最近几乎所有的Java都实现有分代垃圾收集。另外,函数型语言OCaml也采用了分代垃圾收集。
保守垃圾收集
像C这种本来没有垃圾收集的语言,编译之后没有保留区别整数和指针的信息,因为CPU对两者不加区分,所以也就没这个必要。通常,垃圾收集的实现需要明确区分引用(指针),而C和C++没有这样的功能,在这样的环境下实现垃圾收集的技巧之一称为保守垃圾收集。
其基本思想就是如果碰巧有整数的值与引用相同的话,该对象就有可能被引用,就当它是活着的。保守就是倾向于安全的意思。与此相对,能够明确区别所用的环境下的垃圾收集称为精确垃圾收集。
因为倾向于安全一面,保守垃圾收集在C或者C++这样没有垃圾收集功能的语言中也可以得到实现,这是它的优点。但是,本来应该回收的对象却在意料之外保留下来不能回收,这是它的缺点。以及,它不能喝复制垃圾收集这样需要移动的垃圾收集算法组合使用。
Ruby采用的是保守垃圾收集。局部变量可以按照通常语言的访问路径来处理,系统堆栈部分是当做指针数组来扫描的。Ruby大部分是用C编写的,因为有了保守垃圾收集,C库的实现变得非常简单。实际上,Python和Perl因为采用的是引用计数器,C例程内部的引用数管理非常复杂,偶然忘记增减就会发生内存问题。但是,用C编写Ruby扩展库时,基本上不用操心内存管理,好处十分明显。
Boehm GC为C和C++增加了垃圾收集功能。Boehm GC也同时实现了分代垃圾收集。Boehm GC不仅用于C和C++,在Scheme处理系统Gauche等多种语言处理系统中,也作为垃圾收集功能得到广泛的应用。
增量垃圾收集
在实时性要求高的程序中,垃圾收集带来的中断时间必须是可预测的。为保证实时性,不需要等垃圾收集完全执行结束,而是要把垃圾收集细分正许多细小的片段,每次执行一点,这叫增量垃圾收集。
增量垃圾收集在垃圾收集处理过程中程序也在同时执行,引用有可能会改变。结果是垃圾收集的一致性不能得到保证。增量垃圾收集为避免这样的问题,采用了与保守垃圾收集相同的写屏蔽操作。
嵌入式处理系统采用的是增量垃圾收集。有名的Io和Lua都实现了增量垃圾收集。
并行垃圾收集
在多核环境下,灵活运用线程可以最大限度地发挥多个CPU的能力。并行垃圾收集就是要最大限度利用多个CPU的能力。
并行垃圾收集基本原理与增量垃圾收集大致是一样的,都是利用写屏蔽来维护当前状态的信息。有的并行垃圾收集的实现生成垃圾收集专用线程,把垃圾收集设计成总是与普通处理并行执行。
位图标记
以Linux为首的UNIX系列操作系统在使用fork系统调用复制过程时,内存空间并不进行复制而是直接共享。通过写时复制来提高性能。
垃圾收集与这一功能兼容性不好,给引用对象那个设置标记的方式会因设置标记而复制包含该对象的内存页。复制方式也同样会产生大量写内存操作。
位图标记是在利用标记的垃圾收集中消减操作系统内存页复制的方法。它不在对象里设置被引用的标记,而是利用外部位图区域(管理用内存区域)来保存引用标记。
只有标记用的位图部分会发生内存页复制,从而避免了复制没有实际更新的对象所在的内存页。
Ruby的垃圾收集也有了实现位图标记的补丁。
用C语言来扩展Ruby
Ruby是解释型语言,即Ruby程序是由Ruby解释器的程序来解释执行的。
提起解释器,大家会觉得它是逐行读取程序并执行,实际上Ruby解释器是把要执行的程序全部读进来,首先变换成更有效率的内部表现形式。解释器对其内部表现加以分析来执行程序。
解释型语言的特点,马上可以执行,开发周期非常快。至于C、C++、Java这样的编译语言,首先要把程序变换成计算机可以直接执行的形式再从头执行。
在执行程序过程中,编译型语言不再需要对原来程序进行解释和变换,速度很快。但是开发周期较长。
开发与执行速度的取舍
这两种类型的语言要做取舍。Ruby的设计方针是开发效率优于执行效率,选择解释型的实现也是必然。
Ruby解释器是由C语言开发的,采用C语言开发理由:
- C语言作者拿手
- C语言运行系统调用,速度高
- 用面向对象语言来实现别的面向对象语言的话,容易混淆对象的概念。
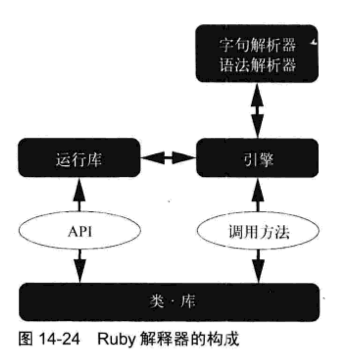
引擎是解释内部表现,并实际上执行程序的部分。1.9版本的引擎解释的字节码,可以说是近似于虚拟计算机的机器语言。所以1.9版本的引擎也可以成为VM。
引擎在解释内部表现是,需要其他组件的帮助。内存和对象的管理,变量访问和方法调用的实现等,都要依靠底层称为运行库的组件来完成。运行库提供底层强有力的支持,是程序执行时不可或缺的部分。
Ruby利用的各种类是类库提供的。Ruby的这一部分也是用C编写的。像Ruby这样的解释型语言,因为是经过C编写的引擎来间接执行程序,与一般的编译语言相比,执行速度明显慢得多(100 倍或者 1000 倍)。但是,实际上程序的执行时间大部分都花在 C 編写的类库方法内部,因此在执行速度上很少会产生那么巨大的差距。
扩展库
扩展库是指利用Ruby运行库的API,用C定义的类库。Ruby的API使用C几乎可以实现Ruby所有的功能。使用这些API可以很简单地实现如下的功能:
- 定义类
- 定义方法
- 访问实例变量
- 调用方法
- 调用块
特意花时间用C来实现扩展库的理由主要有以下两点。
- 想要比Ruby执行速度快
- 想使用C可以利用的库。
前面已经说过,Ruby是解释型语言,它的执行速度不如像C这样的编译型语言。如果是绝对需要改善速度的程序,用C扩展库来实现其中成为瓶颈的部分的话,有可能显著改善程序的
执行速度。
UNX系列操作系统的大多数功能都是通过C可以访问的库来提供的。Ruby要想利用这些功能的话,就需要有一种从Ruby调用C的API的方法,这最简单的方法就是利用扩展库。
扩展库的编译
首先按照以上的顺序编写源代码。若C程序的文件名后
约定为c的话,后续步骤会自动识别出来C程序文件。
为生成编译所需要的文件,需要准备必要的
Ruby文件。这个文件通常命名为 extconf.rb
minitab的 extconf.rb的内容如图所示
extons,xb是由以下几个部分构成的:
- 调用 require’mkmf’;
- 用have_1 ibrary和 hava header检
查必要的库和头文件是否存在; - 用 create makefile来生成必要的
Makefile. create makefile的参数
是库的名字。
照图14-34执行 extconfrb,就可以生成
Makefi1e。
用make命令来编译,尔后可以用 make insta11命令来安装编译后的库。
扩展库之外的工具
RubyInline
Rubylnline可以在Ruby的源代码中直接嵌入C的程序。不用每次准备 exton,rb文件,也不需要明确的编译步骤,非常便利,但它也有不少约束,比如在执行环境中需要有编译器,与外部库的链接也有些麻烦等。
dl
有了d1,仅用Ruby也能实现与 minitab同样动作的库。把图1435的程序保存成 inial,rb文件,没有扩展库也可以使用 minitab。al的优点是在没有安装编译器和头文件的环境下也可以运行。
ffi
关于Ruby的扩展,ffi库受到关注。ffi是 foreign function interface的缩写,它也提供在Ruby水平上的与外部函数的直接接口,这个目的与d1几乎是一样的。ffi可以从 Ruby Gems得到。ffi的特征是使用lb更有效率地调用外部函数,Ruby、 Rubinius和 GRubby都可以使用
同样的API。
为什么要开源
自由软件的思想
为保证执行的自由,必须能够将软件免费拿到手。出于学习和研究的目的,也必须能够自由地得到源代码。还有,为了修改程序错误,或者为适合自己的目的而进行改造,那就不单单
是阅读源代码,还要允许改变源代码。把自己认为好的软件推荐给别人,或者把自己进行的修改或改善与他人共享的话,就需要有再发布的自由。
自由软件的历史
曾几何时,在计算机的黎明期,软件完全是硬件的附属物。买了计算机,附带操作系统等源代码,根本就不是什么稀罕的事。那时,或者在更早一些的时候,甚至有这样的情况,从生
产厂家买来的计算机连操作系统也没有,需要用户自己来开发各种软件。买了同样计算机的用户互相交换自己开发的软件,互助合作。虽然不够精致,但与如今开源软件的情况很有些相似之处。
Emacs事件的发生
但是,戈斯林把 Gosmacs的专利卖给了 Unipress公司,斯托曼就不能够在 Gosmacs的基础上开发新的 Emacs了。结果,斯托曼从零开始开发了自己的UNIX版的Emacs。
他们的最终目标是,创造一个从上到下完全自由的操作系统环境。
开源的诞生

OSS许可证
GPL
GPL( GNU General Public license)应该可以说是自由软件许可证的鼻祖,它具有如下特征:
- 没有保证;
- 表示版权;
- 保持同样的许可证
GPL特征中最重要的是保持同样的许可证,也就是说,在对GPL许可证的软件进行修改或复制的情况下,必须保持其原来的GPL许可证。
这意味着再利用GPL软件的源代码而开发的软件的许可证也必须是GPL。批判GPL的人把这称为感染性。赞同GPL的人们称之为版权保留,因为这一性质意味着版权的保留。
LGPL
BSD许可证
APL和CPL
开源的背景
在科学领域,共享知识和信息本来是非常普通的事情。即使不用看站在巨人的肩膀上的牛顿的例子,把知识作为论文(免费)公开,利用前人的成绩进行新的研究是再理所当然不过的。
软件,特别是商业软件,一旦作为商品来经营的话,就容易忘记这样一点,与论文的内容一样,软件也不过是信息的一种,也应该适用同样的原则。科学家致力于研究,大学或研究机构对科学家给予支持,这种体制对软件也有可能成立。实际上,大学或研究机构支援软件开发的例子相当多。
但是,谈到近年来开源的普及和发展,计算机的普及和因特网的发展则功不可没。过去如果要想开发髙质量软件的话,需要购买价格髙昂的计算机,召集大量的技术人员。现在一般家庭里的计算机都完全能够开发软件,通过网络进行合作开发的事情也屡见不鲜。个人出于兴趣而编程也已经能够达到相当高的水平了。
软件的复杂化和商品化也是开源的背景之一,不容忽视。软件所覆盖的领域越来越广,软件也越来越复杂。过去1万行左右的程序就实现了的操作系统,如今变成了超过600万行的巨大软件。
企业关注开源的理由
从1998年以来,开始出现了盈利企业为自己的利益而开发开
源软件的事例。一旦认识到无法自己来开发所有软件之后,企业只自己开发最具竞争力的小部分核心软件,而让大家共同来开发其他软件,结果对大家都有好处,企业关注开源正是这种冷静的分析考量的结果。
参与开源的人们也各有各的想法。有因经营考虑而参加的企业,有为软件自由而参加的程序员,有因上级命令而参加的公司职员,各种各样,千差万别。但是,开源有可能为个人和全人类带来幸福,如果能继续下去形成良性循环的话,那真是再好不过了。
Ruby与开源
Ruby从一开始就是开源软件。Ruby在1995年初次公开的时候,开源这个单词还没有诞生,也许应该称为自由软件。
选择许可证的方法
许可证与技术无关,而是有关法律和合同的工作,这不是技术人员的工作,而是属于律师的工作范围。对于软件开发人员来说,这决不是一件令人感兴趣的工作,有人甚至会想:“哪用得着这些东西呢?”
如果使用你的许可证的软件的所有代码都完全是由你自己写出来的话,这几乎不成为什么问题。只要发布新的许可证版本,问题就解决了但是,如果其中包含了其他人写的补丁的话,软件就不再是你一个人的了,在法律上写补丁的人是共同拥有版权的。
FSF作为软件自由的拥护者,强烈推行版权保留。另一方面,不怎么在乎版权保留的开发人员好像更多一些。如果你希望版权保留的话,几乎就只能选择GPL。
如果你的软件是作为库来使用的话,那么LGPL则是个不错的选择。如果对库适用GPL许可证的话,那事实上就只能为GPL软件所用,采用限制较为宽松的LGPL的话,有可能使你的软件得到更为广泛的使用。但是,LGPL有不方便、难于理解以及没有得到充分考察等缺点,在不太强烈希望版权保留的时候,最好不要选择它。
对于不太在乎版权保留的人来说,可以选择GPL以外的许可证。这里的要点是,该软件是否需要与其他软件进行链接。如果预想到将来可能以某种方式与GPL许可证的软件链接在一起的话,那么与GPL的互换性就变得很重要。拥有插件功能的软件或库特别要注意这一点。作为与GPL不相矛盾的许可证,有修正BSD许可证和MIT许可证等。
另一个应该考虑的要点是,与相关软件和许可证是否一致。比如 Eclipse插件就应该选择Eclipse许可证(即使不与GPL互换)。另外,PHP关联软件选择与PHP一致的许可证也是安全的。用Ruby编写的软件与Ruby本身的许可证本来是相互独立的,但好像也大都选择Rby许可证。