Tensorflow计算模型–计算图
计算图的使用
tensorflow程序可分为两个阶段,第一阶段定义图中所有的计算。第二阶段为执行阶段。
tensorflow中,系统会自动维护一个默认的计算图,通过tf.get_default_graph函数可以获取当前默认的计算图。
除了使用默认的计算图,Tensorflow支持通过tf.Graph函数来生成新的计算图。不同计算图上的张量和运算都不会共享。
计算图可以通过tf.Graph.device函数来指定运行计算的设备。
有效地整理TensorFlow程序的资源也是计算图的一个重要功能。在一个集合(collection)来管理不同类型的资源。
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
| tf.GraphKeys.VARIABLES | 所有变量 | 持久化Tensorflow模型 |
| tf.GraphKeys.TRAINABLE_VARIABLES | 可学习的变量(一般指神经网络中的参数) | 模型训练、生成模型可视化内容 |
| tf.GraphKeys.SUMMARIES | 日志生成的相关的张量 | TensorFlow计算可视化 |
| tf.GraphKeys.QUEUE_RUNNERS | 处理输入的QueueRunner | 输入处理 |
| tf.GraphKeys.MOVING_AVERAGE_VARIABLES | 所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
如通过tf.add_to_collection将资源加入一个或多个集合中。通过tf.get_collection获取一个集合里面的所有资源。
tf.add_to_collection(‘losses’,regularizer(var_weights)):将数值regularizer(var_weights)添加到集合‘losses’中
tf.get_collection(‘losses’):获取集合“losses”中的所有元素,生成一个列表并返回该列表
TensorBoard可视化
TensorBoard简介
TensorBoard可以通过TensorFlow程序运行过程中输出的日志文件可视化TensorFlow程序的运行状态。两者跑在不同进程中,TensorBoard会自动读取TensorFlow最新的日志文件。
#运行TensorBoard,将地址执行日志输出地址
tensorboard –logdir=/path/to/log
命令启动服务默认端口号6006,localhost:6006可以看到界面。使用–port参数可以改变启动服务的端口。
变量管理
TensorFLow提供了通过变量名称来创建或者获取一个变量的机制。通过这个机制在不同的函数中可以直接通过变量的名称来使用变量,而不需要将变量通过参数的形式到处传递。TensorFLow中通过变量名称获取变量的机制主要是通过tf.get_variable和tf.variable_scope函数实现。
v.get_variable和tf.Variable定义等价。区别在于前者变量名称是个必填项,后者是个选填项。v.get_variable会根据这个名字去创建或者获取变量。首先会试图创建一个变量,如有同名则创建失败。如果需要通v.get_variable获取一个已经创建的变量,需要tf.variable_scope函数生成一个上下文管理器。将参数reuse设置为True(获取唯一途径),v.get_variable将只能获取已经创建过的变量。否则将尝试创建变量。
with tf.variable_scope(“name”,reuse=”True”):
v=v.get_variable(“var”,[1])
tf.variable_scope会创建一个命名空间。foo/v:0 “:0”表示这个变量是生成变量这个运算的第一个结果。
TensorFlow计算图可视化
命名空间与TensorBoard图上节点
变量的初始化过程也会产生新的计算节点。为了更好的组织可视化效果图中的计算节点,TensorBoard支持通过TensorFlow命名空间来整理可视化效果图上的节点。在Tensorflow默认视图中同一命名空间计算图为一个节点,只有顶层命名空间的节点显示。
除了tf.Variable_scope函数,tf.name_scope函数也提供了命名空间管理的功能,两者大部分情况下等价。唯一的区别是tf.get_Variable不受tf.name_scope函数的影响。即在tf.name_scope域里tf.get_Variable生成变量也不是域内的变量。
节点之间有两种不同的边,一种是通过实线表示的,刻画了数据传输,箭头表示传输方向。另一种箭头是双向的,表示会修改,会互相影响。
TensorBoard边上标注了张量的维度信息。如100*784说明batch为100,输入节点个数为784,粗细代表维度的总大小。若张量数量大于1时。图上将只显示张量的个数。
虚线表示计算之间的依赖关系,如tf.control_dependencies函数指定操作同时进行。则存在虚线。
TensorBoard会自动将连接比较多的节点放在辅助图中,可以手动移入主图或移出主图。TensorBoard不会保存用户对计算图可视化结果的手工修改,页面刷新之后计算图可视化结果又会回到最初的样子。
节点信息
使用TensorBoard可以非常直观地展现所有Tensorflow计算节点在某一次运行时所消耗的时间和内存。
run_options =tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
// 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
m, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
//将节点在运行时的信息写入日志文件。 writer.add_run_metadata(run_metadata=run_metadata,tag=(“tag%d” % i),global_step=i)
使用程序输出的日志启动TensorBoard,就可以了。进入GRAPHS栏,选择Session runs,Color会出现Compute time和Memory这两个选项。颜色越深消耗越大。Structure中如果有两个节点结构相同就会涂上相同的颜色。Device中可显示哪些使用了相同的设备(CPU/GPU)。
点击节点时弹出的信息卡片也会显示这个节点的各种信息。
监控指标可视化
| TensorFlow日志生成函数 | TensorBoard界面栏 | 显示内容 |
|---|---|---|
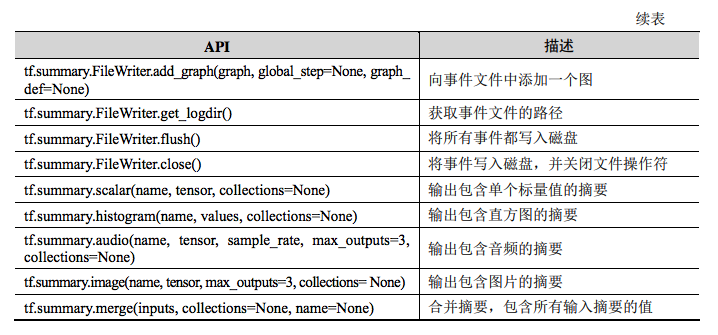
| tf.scalar_summary | EVENTS | TensorFlow中标量(scalar)监控数据随着迭代进行的变化趋势。 |
| tf.image_summary | IMAGES | TensorFlow中使用的图片数据,这一栏一般用于可视化当前使用的训练/测试图片。 |
| tf.audio_summary | AUDIO | TensorFlow中使用的音频数据。 |
| tf.histogram_summary | HISTOGRAMS | TensorFlow中张量分布监控数据随着迭代轮次的变化趋势。 |
上述生成函数都不会立即执行,需要通过sess.run来明确调用这些函数。tf.merge_all_summaries()可将定义的所有日志文件执行一次。
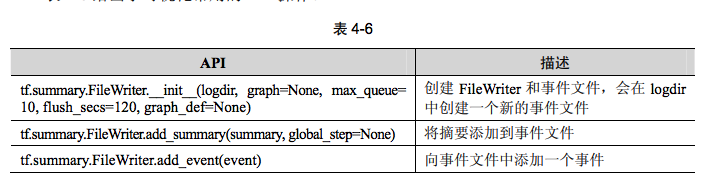
writer
writer=tf.train.SummaryWriter(path,tf.get_default_graph())
writer.close()
或者
with tf.Session() as sess:
writer=tf.train.SummaryWriter(path,sess.graph)
上述比较过时,若报错则改为writer = tf.summary.FileWriter(“output”, sess.graph)
可视化时,需要在程序中给必要的节点添加摘要(summary),摘要会收集该节点的数据,并标记上第几步、时间戳等标识,写入事件文件(event file)中。tf.summary.FileWriter类用于在目录中创建事件文件,并且向文件中添加摘要和事件,用来在TensorBoard中展示。